パトリック・シルベストル さん




前の10件 | -
Rによる隠れマルコフモデル [R]
大学院のゼミでPRML を読んでいる。私の担当は13章「系列データ」の後半の「状態空間モデル」(SSM: State Space Model)である。13章の前半は「隠れマルコフモデル」(HMM: Hidden Markov Model)について記述されている。SSMは日本のお家芸であり、統計数理研究所の先代所長の北川先生や現所長の樋口先生により発展した。ところが、SSMの離散バージョンだと言われているHMMはなぜかあまり日本ではクローズアップされていない。PRMLはHMM→SSMの順番で記述されているので、丁度良い機会だからついでにHMMについて勉強しようと思ってこのブログをアップした。
を読んでいる。私の担当は13章「系列データ」の後半の「状態空間モデル」(SSM: State Space Model)である。13章の前半は「隠れマルコフモデル」(HMM: Hidden Markov Model)について記述されている。SSMは日本のお家芸であり、統計数理研究所の先代所長の北川先生や現所長の樋口先生により発展した。ところが、SSMの離散バージョンだと言われているHMMはなぜかあまり日本ではクローズアップされていない。PRMLはHMM→SSMの順番で記述されているので、丁度良い機会だからついでにHMMについて勉強しようと思ってこのブログをアップした。
とりあえず、はじめからアルゴリズムを実装するのは私の実力では厳しいので、Rのパッケージで遊んでみよう思ってあれこれ探したところ、{RHmm}というパッケージが見つかった。このパッケージについてはいくつかの日本語ブログで言及されているものの、既にCRANから削除されてしまっている。なんじゃ。と思い、いろいろ調べてみると、{depmixS4}というHMMのパッケージが見つかった。これは最近でも更新されているし、R-bloggerでも紹介されているので間違いないと思って、こちらをいじってみることにした。
(本記事では理論については書いていない。理論について知りたい方はPRML等を参照のこと。)
このパッケージにはSpeedというサンプルデータがあって、これを基にサンプルコードが展開されている。ヘルプには詳しく書かれていなかったが、どうやら心理学のスピードと正確性のトレードオフに関する実験データのようである。
■Speedデータ
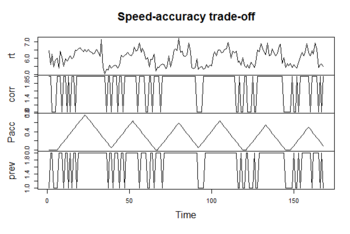
■Rコード
次のコードによりパッケージを読み込んでSpeedデータを可視化する。
次に隠れマルコフモデルを構築する。手始めに隠れ状態 = 2 と想定する。隠れ状態は恣意的に設定するが、AICやBICを参照することで最適な隠れ状態を設定することが可能であるっぽい(勉強中)。以下のコードにて、depmixオブジェクトを作って、EMアルゴリズムでパラメータを推定。
次にモデル推定結果を出力。先ずは情報量の確認。
ちなみに、隠れ状態 = 1 の場合には、AIC = 614.6619, BIC = 622.8309 となることから、上記の隠れ状態 = 2 の方がAICもBICも低いため良いモデルという評価となった。次に推定されたパラメータを確認。
Transition matrixを見ると、推移確率は以下のように推定されたということ。
S1⇒S1: 0.9156683
S1⇒S2: 0.08433171
S2⇒S2: 0.1164891
S2⇒S1: 0.88351091
次に、"Response parameters"の解釈だが、これはおそらく推定された各隠れ状態(S1・S2)におけるレスポンス時間(rt)の平均と分散を記述していると思われる(勉強中のため断言できず)。
最後に、Viterbiアルゴリズムによって潜在変数系列を推定した上で結果を可視化すると次のようになる。
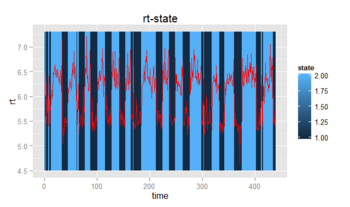
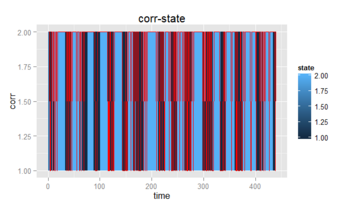
レスポンス時間が落ちていて、かつ誤答が多い部分が認識されていることが分かります。このように隠れマルコフモデルを用いることで、時系列データを離散分離することができるようです。未だ勉強始めたばかりでわからないことだらけですが、そのうちまた続編を書きたいと思います。
■参考文献
")
やっぱりこれが日本語で読める一番詳しい本です。状態空間モデルとの関係が分かりやすいです。
")
洋書ですがRコードが開示されていて分かりやすいです。具体的事例もいくつかあります。
とりあえず、はじめからアルゴリズムを実装するのは私の実力では厳しいので、Rのパッケージで遊んでみよう思ってあれこれ探したところ、{RHmm}というパッケージが見つかった。このパッケージについてはいくつかの日本語ブログで言及されているものの、既にCRANから削除されてしまっている。なんじゃ。と思い、いろいろ調べてみると、{depmixS4}というHMMのパッケージが見つかった。これは最近でも更新されているし、R-bloggerでも紹介されているので間違いないと思って、こちらをいじってみることにした。
(本記事では理論については書いていない。理論について知りたい方はPRML
このパッケージにはSpeedというサンプルデータがあって、これを基にサンプルコードが展開されている。ヘルプには詳しく書かれていなかったが、どうやら心理学のスピードと正確性のトレードオフに関する実験データのようである。
■Speedデータ
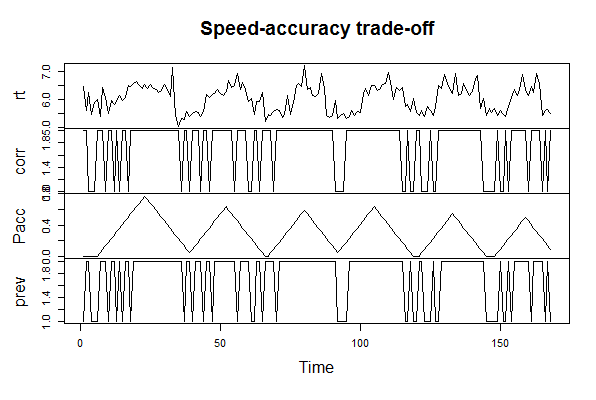
rt: レスポンス時間(response time)
corr: 正答スコア(1/0) (accuracy scores)
pacc: 正確性に注意を払っている度合い (the pay-off for accuracy)
prev: 1期前の正答スコア(1/0) (accuracy scores (0/1) on the previous trial)
■Rコード
次のコードによりパッケージを読み込んでSpeedデータを可視化する。
#####Library library(depmixS4) #####Data data(speed) #####Visualization plot(as.ts(speed[1:168,]), main = "Speed-accuracy trade-off")
次に隠れマルコフモデルを構築する。手始めに隠れ状態 = 2 と想定する。隠れ状態は恣意的に設定するが、AICやBICを参照することで最適な隠れ状態を設定することが可能であるっぽい(勉強中)。以下のコードにて、depmixオブジェクトを作って、EMアルゴリズムでパラメータを推定。
##### Modeling set.seed(1) mod <- depmix(response = rt ~ 1, data = speed, nstates = 2, trstart = runif(4)) fm <- fit(mod) #EMアルゴリズムによるパラメータ推定
次にモデル推定結果を出力。先ずは情報量の確認。
print(fm) # Convergence info: Log likelihood converged to within tol. (relative change) # 'log Lik.' -88.73058 (df=7) # AIC: 191.4612 # BIC: 220.0527
ちなみに、隠れ状態 = 1 の場合には、AIC = 614.6619, BIC = 622.8309 となることから、上記の隠れ状態 = 2 の方がAICもBICも低いため良いモデルという評価となった。次に推定されたパラメータを確認。
summary(fm) # Initial state probabilties model # pr1 pr2 # 1 0 # # # Transition matrix # toS1 toS2 # fromS1 0.9156683 0.08433171 # fromS2 0.1164891 0.88351091 # # Response parameters # Resp 1 : gaussian # Re1.(Intercept) Re1.sd # St1 6.385053 0.2441601 # St2 5.510363 0.1917513
Transition matrixを見ると、推移確率は以下のように推定されたということ。
S1⇒S1: 0.9156683
S1⇒S2: 0.08433171
S2⇒S2: 0.1164891
S2⇒S1: 0.88351091
次に、"Response parameters"の解釈だが、これはおそらく推定された各隠れ状態(S1・S2)におけるレスポンス時間(rt)の平均と分散を記述していると思われる(勉強中のため断言できず)。
最後に、Viterbiアルゴリズムによって潜在変数系列を推定した上で結果を可視化すると次のようになる。
##### Viterbiアルゴリズムによる系列推定
result <- posterior(fm)
result$rt <- speed$rt
result$time <- seq(1,439)
#rt-state
gg1 <- ggplot(data=result,aes(x=time, y=rt)) +
geom_rect(aes(fill = state, xmin = time - 0.5, xmax = time + 0.5, ymin=4.5,
ymax = max(rt) + 0.1)) +
geom_line(colour="red", size=0.5)
print(gg1)
#corr-state
gg2 <- ggplot(data=result,aes(x=time, y=corr)) +
geom_rect(aes(fill = state, xmin = time - 0.5, xmax = time + 0.5, ymin=1.0,
ymax = 2.0)) +
geom_line(colour="red", size=0.5)
print(gg2)
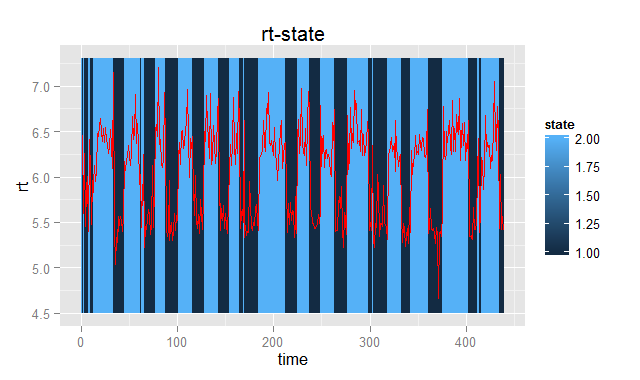
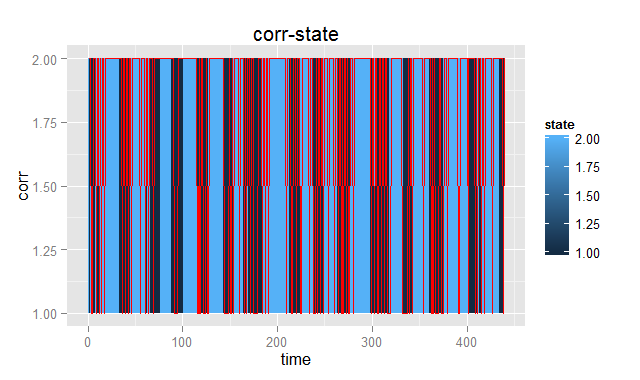
レスポンス時間が落ちていて、かつ誤答が多い部分が認識されていることが分かります。このように隠れマルコフモデルを用いることで、時系列データを離散分離することができるようです。未だ勉強始めたばかりでわからないことだらけですが、そのうちまた続編を書きたいと思います。
■参考文献
- 作者: C.M. ビショップ
- 出版社/メーカー: 丸善出版
- 発売日: 2012/02/29
- メディア: 単行本
やっぱりこれが日本語で読める一番詳しい本です。状態空間モデルとの関係が分かりやすいです。
- 作者: Walter Zucchini
- 出版社/メーカー: Chapman and Hall/CRC
- 発売日: 2009/04/30
- メディア: ハードカバー
洋書ですがRコードが開示されていて分かりやすいです。具体的事例もいくつかあります。
CentOS6.5にRStudio Serverをインストール [R]
WindowsXPのサポート終了に伴い、自宅PCのOSをCentOSに移行しました。なので、分析環境もいちから出直し。Rのインストールはすんなりいったのだけど、RStudio Serverがインストールできない。頑張って解決したので、Tipsをメモっておきます。
■インストール
ところが、これではインストールできない。
→Errorになってしまった。失敗。
■やり直し
→こっちで成功。"--nodeps"というのがポイントだったみたい。
■以降のコマンド
・参照サイト
http://d.hatena.ne.jp/hiratake55/20120527/1338091311
・インストールできているか確認
・RStudio Serverを起動
・システム起動時に自動起動する


■インストール
rpm -Uvh rstudio-server-0.98.507-i686.rpm
ところが、これではインストールできない。
エラー: 依存性の欠如:
libR.so は rstudio-server-0.98.507-1.i686 に必要とされています
libRblas.so は rstudio-server-0.98.507-1.i686 に必要とされています
libRlapack.so は rstudio-server-0.98.507-1.i686 に必要とされています
→Errorになってしまった。失敗。
■やり直し
rpm -Uvh --nodeps rstudio-server-0.98.507-i686.rpm
→こっちで成功。"--nodeps"というのがポイントだったみたい。
■以降のコマンド
・参照サイト
http://d.hatena.ne.jp/hiratake55/20120527/1338091311
・インストールできているか確認
rstudio-server verify-installation
・RStudio Serverを起動
rstudio-server start
・システム起動時に自動起動する
chkconfig rstudio-server on
chkconfig --list rstudio-server
- 作者: 中島 能和
- 出版社/メーカー: 翔泳社
- 発売日: 2012/03/09
- メディア: 大型本
Rで学ぶデータ・プログラミング入門 ―RStudioを活用する―
- 作者: 石田 基広
- 出版社/メーカー: 共立出版
- 発売日: 2012/10/24
- メディア: 単行本
Pythonで状態空間モデリング(1) -時変の平均をもつ時系列モデルの状態空間表現(その1)- [統計学]
最近はPythonをデータ分析に活用する動きが活発になっている。Rとともに2大勢力になってきている。ついに「Pythonによるデータ分析入門 ―NumPy、pandasを使ったデータ処理 」という邦訳本も出版されたことだし、日本でもPythonをデータ分析に使う人が増えると思われる。予測モデルを作る際には一般的にはscikit-learnを使うわけだが、こちらは英語のリファレンスしかないので普及にはもう少し時間がかかるだろう。おそらく、scikit-learnについての日本語の解説書もそのうち出版されるのではないかと思っている。
」という邦訳本も出版されたことだし、日本でもPythonをデータ分析に使う人が増えると思われる。予測モデルを作る際には一般的にはscikit-learnを使うわけだが、こちらは英語のリファレンスしかないので普及にはもう少し時間がかかるだろう。おそらく、scikit-learnについての日本語の解説書もそのうち出版されるのではないかと思っている。
さて、私は状態空間モデリングの勉強を姜先生の「ベイズ統計データ解析 (Rで学ぶデータサイエンス 3) 」という本を使って進めている。この本はカルマンフィルタのRでの実装が記載されており、実に有用である。難しい数式が並ぶカルマンフィルタも実際のコードを解釈しながら勉強すると比較的シンプルで理解しやすことが分かった。
」という本を使って進めている。この本はカルマンフィルタのRでの実装が記載されており、実に有用である。難しい数式が並ぶカルマンフィルタも実際のコードを解釈しながら勉強すると比較的シンプルで理解しやすことが分かった。
さらに勉強を進めるべく本のRコードをPythonに翻訳してみた。このような翻訳作業によって状態空間モデリングとPythonの両方を一篇に身に着けてしまおうとある時に思いついた。これはなかなか学習効率がよいので今後も続けてみようと思う。やっぱり統計や機械学習の勉強はコーディングしてみるのが近道である。今回の記事では姜先生の本の7章を解説しつつRコードをPythonにへの翻訳を紹介する。
◆状態空間モデリング
・状態空間モデリングは時系列モデルの一種であり、非定常時系列をモデル化することができる。
・伝統的なARIMAモデルなどの時系列モデルを統一的に扱うことができる。
・カルマンフィルタなどの推定アルゴリズムが一見難しいのと分かりやすいRパッケージが少ないためか、あまり一般に普及していない気がする。姜先生の本はコードもあるし分かりやすいのでもっと読まれるべきであろう。
・状態空間モデルは次のようにシンプルな形をしている2つの式から構成される(状態空間表現と呼ばれている)。ところが、この式に複数の要素を導入でき複雑なモデルを構築することができる。シンプルさと複雑さが同居するところが面白いところだ。
・潜在変数を扱えるところもこのモデルの特徴。しかもモデラーの感覚を柔軟に式に導入することができる。これが最大の魅力と現時点では考えている。
【状態空間表現】
・システムモデル
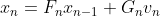
)
・観測モデル
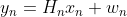
)
◆今回の事例:「時変の平均をもつ時系列モデルの状態空間表現」
・時変の平均をもつ時系列モデルを状態空間表現にしてみる
【時変の平均をもつ時系列モデル】
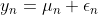
)
【潜在的な平均の推移】
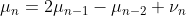
)
【状態空間表現】
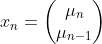 ,
,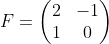 ,
,
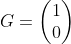 ,
,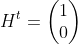 ,
,
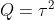 ,
, 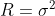
【Pythonコード】
(次回へ続く)

")
さて、私は状態空間モデリングの勉強を姜先生の「ベイズ統計データ解析 (Rで学ぶデータサイエンス 3)
さらに勉強を進めるべく本のRコードをPythonに翻訳してみた。このような翻訳作業によって状態空間モデリングとPythonの両方を一篇に身に着けてしまおうとある時に思いついた。これはなかなか学習効率がよいので今後も続けてみようと思う。やっぱり統計や機械学習の勉強はコーディングしてみるのが近道である。今回の記事では姜先生の本の7章を解説しつつRコードをPythonにへの翻訳を紹介する。
◆状態空間モデリング
・状態空間モデリングは時系列モデルの一種であり、非定常時系列をモデル化することができる。
・伝統的なARIMAモデルなどの時系列モデルを統一的に扱うことができる。
・カルマンフィルタなどの推定アルゴリズムが一見難しいのと分かりやすいRパッケージが少ないためか、あまり一般に普及していない気がする。姜先生の本はコードもあるし分かりやすいのでもっと読まれるべきであろう。
・状態空間モデルは次のようにシンプルな形をしている2つの式から構成される(状態空間表現と呼ばれている)。ところが、この式に複数の要素を導入でき複雑なモデルを構築することができる。シンプルさと複雑さが同居するところが面白いところだ。
・潜在変数を扱えるところもこのモデルの特徴。しかもモデラーの感覚を柔軟に式に導入することができる。これが最大の魅力と現時点では考えている。
【状態空間表現】
・システムモデル
・観測モデル
◆今回の事例:「時変の平均をもつ時系列モデルの状態空間表現」
・時変の平均をもつ時系列モデルを状態空間表現にしてみる
【時変の平均をもつ時系列モデル】
【潜在的な平均の推移】
【状態空間表現】
【Pythonコード】
#!/usr/bin/env python #-*- coding:utf-8 -*- ##package import numpy as np ##define Matrix L = 1; k = 2; m = 1 F = np.zeros((k, k)); G = np.zeros((k, m)) H = np.zeros((L, k)); R = np.identity(L) F[0][0] = 2; F[0][1] = -1; F[1][0] = 1 G[0][0] = 1; H[0][0] = 1
(次回へ続く)
Pythonによるデータ分析入門 ―NumPy、pandasを使ったデータ処理
- 作者: Wes McKinney
- 出版社/メーカー: オライリージャパン
- 発売日: 2013/12/26
- メディア: 大型本
- 作者: 姜 興起
- 出版社/メーカー: 共立出版
- 発売日: 2010/07/24
- メディア: 単行本
ビッグデータ分析の本当に面白いところ [ビッグデータ]
1年以上ぶりの更新である。おかげさまで仕事が忙しすぎてブログどろこではなかった。
さて、統計数理研究所の公開講座「マイクロマーケティングとベイジアンモデリング」に参加した。キーワードは、「マーケティング」、「ビッグデータ」、「ベイズ」といったところで、最近のホットトピックスに対して数理的なアプローチでどのようなことができるのかという2日間の講義だった。
感想は、とても有意義な2日間でこれで5000円ですか!というぐらいの充実ぶりだった。ぜひ、来年も実施して頂きたい。昨年、「ビッグデータ時代のマーケティング―ベイジアンモデリングの活用」 という本を出版された稀代の数理マーケティング学者である佐藤先生とその師匠である統数研所長の樋口先生のタッグによる状態空間モデルの講義は非常に分かりやすく、目から鱗(流石!)。このお二人の出版されている本は非常に有益なのでこの記事の最後にリンクしておく。ビッグデータの本当のところを理解したいならセットで読むべき本だろう。
という本を出版された稀代の数理マーケティング学者である佐藤先生とその師匠である統数研所長の樋口先生のタッグによる状態空間モデルの講義は非常に分かりやすく、目から鱗(流石!)。このお二人の出版されている本は非常に有益なのでこの記事の最後にリンクしておく。ビッグデータの本当のところを理解したいならセットで読むべき本だろう。
ビッグデータの課題は、大局的に見るとデータは膨大にあるのだけれど、個人(顧客)に着目するとデータ量が極端に少ないこと。そして、収集されているデータは購買の「結果」であって、そこに至るプロセスや背後にある構造についての情報は通常は観測されない。この状況はセンシング技術が発達しても(おそらく)解決されるものではないだろう。大量のデータが集まっているけど、分析してみると痒いところに手が届かないというのはこのあたりについての洞察が欠けているからだ。
マスコミはこぞってビッグデータを喧伝する。まるで魔法の杖みたいに。でも、そんなことはない。いくらデータが蓄積されても本質的な課題は十分には解決されない。それは、Hadoopで並列計算を行うといったこととは別次元の問題である。この公開講座で紹介されたベイズ的な手法はそこに一つの希望を与えている。
ベイズモデルの魅力は現場の直観を潜在変数として数式に落とし込めるところである。例えば、「参照価格」のようなものは通常は観測できない。しかし、ベイズモデルの枠組みであればこれを潜在変数としてモデルに組み込めてしまう(!) この枠組みでは予測はもちろんだが通常の枠組みでは観測できない隠れた状態のダイナミクスを「推定」して理解することに主眼がある。ここに、データ量の議論を超えた豊かな地平がある。
データが大量にあれば機械学習で勝手に学習するのだ。データサイエンティストは不要になる。という議論があるが、これはあまりに粗雑であるように思う。観測不能なデータは世の中ごまんとある。Webサイトのログは収集できるが、そのときの心情(サイコグラフィックなデータ)は潜在的な構造として存在しており素直には顕在化してくれない。データサイエンティストはその豊かな想像力で仮説を立てて、潜在的な構造を仮定したモデルを作り上げる。これが分析屋の「力量」ということになるであろう。この点については少なくともしばらくは機械にできる知的活動であるとは思えない。
結論。ビッグデータであればあるほど、逆説的にデータの少なさに敏感になろう。そして、人間が持つ豊かな想像力を駆使して大胆にモデルを練り上げよう。ビッグデータ分析の面白さはこのようなところにある。
")
")
さて、統計数理研究所の公開講座「マイクロマーケティングとベイジアンモデリング」に参加した。キーワードは、「マーケティング」、「ビッグデータ」、「ベイズ」といったところで、最近のホットトピックスに対して数理的なアプローチでどのようなことができるのかという2日間の講義だった。
感想は、とても有意義な2日間でこれで5000円ですか!というぐらいの充実ぶりだった。ぜひ、来年も実施して頂きたい。昨年、「ビッグデータ時代のマーケティング―ベイジアンモデリングの活用」
ビッグデータの課題は、大局的に見るとデータは膨大にあるのだけれど、個人(顧客)に着目するとデータ量が極端に少ないこと。そして、収集されているデータは購買の「結果」であって、そこに至るプロセスや背後にある構造についての情報は通常は観測されない。この状況はセンシング技術が発達しても(おそらく)解決されるものではないだろう。大量のデータが集まっているけど、分析してみると痒いところに手が届かないというのはこのあたりについての洞察が欠けているからだ。
マスコミはこぞってビッグデータを喧伝する。まるで魔法の杖みたいに。でも、そんなことはない。いくらデータが蓄積されても本質的な課題は十分には解決されない。それは、Hadoopで並列計算を行うといったこととは別次元の問題である。この公開講座で紹介されたベイズ的な手法はそこに一つの希望を与えている。
ベイズモデルの魅力は現場の直観を潜在変数として数式に落とし込めるところである。例えば、「参照価格」のようなものは通常は観測できない。しかし、ベイズモデルの枠組みであればこれを潜在変数としてモデルに組み込めてしまう(!) この枠組みでは予測はもちろんだが通常の枠組みでは観測できない隠れた状態のダイナミクスを「推定」して理解することに主眼がある。ここに、データ量の議論を超えた豊かな地平がある。
データが大量にあれば機械学習で勝手に学習するのだ。データサイエンティストは不要になる。という議論があるが、これはあまりに粗雑であるように思う。観測不能なデータは世の中ごまんとある。Webサイトのログは収集できるが、そのときの心情(サイコグラフィックなデータ)は潜在的な構造として存在しており素直には顕在化してくれない。データサイエンティストはその豊かな想像力で仮説を立てて、潜在的な構造を仮定したモデルを作り上げる。これが分析屋の「力量」ということになるであろう。この点については少なくともしばらくは機械にできる知的活動であるとは思えない。
結論。ビッグデータであればあるほど、逆説的にデータの少なさに敏感になろう。そして、人間が持つ豊かな想像力を駆使して大胆にモデルを練り上げよう。ビッグデータ分析の面白さはこのようなところにある。
ビッグデータ時代のマーケティング―ベイジアンモデリングの活用 (KS社会科学専門書)
- 作者: 佐藤 忠彦
- 出版社/メーカー: 講談社
- 発売日: 2013/01/22
- メディア: 単行本(ソフトカバー)
予測にいかす統計モデリングの基本―ベイズ統計入門から応用まで (KS理工学専門書)
- 作者: 樋口 知之
- 出版社/メーカー: 講談社
- 発売日: 2011/04/07
- メディア: 単行本(ソフトカバー)
最小二乗法からp値まで [統計学]
線形回帰の基本は最小二乗法を実行して決定係数やp値を確認しながらモデルをブラッシュアップしていくことです。
Rにはlm関数などの便利なものがあるので内部ロジックがどうなっているのか、この関数を使っている限りは気になりません。しかし、いざ人に説明しようとすると内部ロジックに精通する必要が出てきます。というわけで、今日は最小二乗法かp値算出までの線形回帰の基本を確認したいと思います。結構、このあたりをきちんと理解していると次のステップに進みやすいでしょう。
■データ
・今回は次のデータを使います。
■最小二乗法によるパラメータの推定
・線形回帰の場合には最小二乗法=最尤法で次のシンプルな式を解くだけでパラメータを求めることができます。
^{-1}Xy)
・カンタンカンタン!
■決定係数
・修正済み決定係数: γ^2
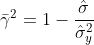
^2)
^2)
■t値
・βの仮説検定を行うにはt値を算出しておく必要があります。
^2}})

■p値
・最後に上記で求めた値からt分布を使ってp値を求めます。
■参考文献

・宮川先生のこの本では線形回帰がとても分かりやすく書かれています。上記のコーディングもこの本を参考にしました。おススメの一冊です。初学者には下記の本よりも分かりやすいことでしょう。(入門書としては下記が紹介されることが多いですが、こちらの方が記載が優しいので下記本に挫折した人でもこちらでリカバリーできる可能性があります。)
")
・この本も分かりやすいですが、入門書を数冊読んだ後の方がよいですね。宮川先生の本を先に一読されることをおススメします。
■全コード
Rにはlm関数などの便利なものがあるので内部ロジックがどうなっているのか、この関数を使っている限りは気になりません。しかし、いざ人に説明しようとすると内部ロジックに精通する必要が出てきます。というわけで、今日は最小二乗法かp値算出までの線形回帰の基本を確認したいと思います。結構、このあたりをきちんと理解していると次のステップに進みやすいでしょう。
■データ
・今回は次のデータを使います。
x <- c(45,33,39,40,42,30,53,45,42,31) #説明変数 y <- c(41,29,36,36,40,26,46,33,35,28) #目的変数 X <- matrix(1,10,2) #行列作成 X[,2] <- x #1列目 = 切片, 2列目=説明変数
■最小二乗法によるパラメータの推定
・線形回帰の場合には最小二乗法=最尤法で次のシンプルな式を解くだけでパラメータを求めることができます。
B <- t(X) %*% X; c <- t(X) %*% y; beta <- solve(B, c) a <- beta[1,]; b <- beta[2,] yhat <- a + b*x
・カンタンカンタン!
■決定係数
・修正済み決定係数: γ^2
#試行錯誤そのままなのでコードが冗長 n <- length(x) sy2 <- sum((y-mean(y))^2)/n sy <- sqrt(sy2) syx2 <- sum((y-a-b*x)^2)/n syx <- sqrt(syx2) sig2 <- n*syx2/(n-2) sig <- sqrt(sig2) sigy2 <- n*sy2/(n-1) rbar2 <- 1 - (sig2/sigy2)
■t値
・βの仮説検定を行うにはt値を算出しておく必要があります。
sx2 <- sum((x-mean(x))^2)/n sx <- sqrt(sx2) siga2 <- sig2 * sum(x^2) /(n^2*sx2) siga <- sqrt(siga2) sigb2 <- sig2/(n*sx2) sigb <- sqrt(sigb2) ta <- a / siga tb <- b / sigb
■p値
・最後に上記で求めた値からt分布を使ってp値を求めます。
pa <- (1 - pt(ta, n-2))*2 pb <- (1 - pt(tb, n-2))*2
■参考文献
- 作者: 宮川 公男
- 出版社/メーカー: 有斐閣
- 発売日: 1999/03
- メディア: 単行本
・宮川先生のこの本では線形回帰がとても分かりやすく書かれています。上記のコーディングもこの本を参考にしました。おススメの一冊です。初学者には下記の本よりも分かりやすいことでしょう。(入門書としては下記が紹介されることが多いですが、こちらの方が記載が優しいので下記本に挫折した人でもこちらでリカバリーできる可能性があります。)
- 作者:
- 出版社/メーカー: 東京大学出版会
- 発売日: 1991/07/09
- メディア: 単行本
・この本も分かりやすいですが、入門書を数冊読んだ後の方がよいですね。宮川先生の本を先に一読されることをおススメします。
■全コード
####DATA
x <- c(45,33,39,40,42,30,53,45,42,31) #説明変数
y <- c(41,29,36,36,40,26,46,33,35,28) #目的変数
X <- matrix(1,10,2) #行列作成
X[,2] <- x #1列目 = 切片, 2列目=説明変数
####Estimation
B <- t(X) %*% X; c <- t(X) %*% y; beta <- solve(B, c)
a <- beta[1,]; b <- beta[2,]
yhat <- a + b*x
####R-squared
n <- length(x)
sy2 <- sum((y-mean(y))^2)/n
sy <- sqrt(sy2)
syx2 <- sum((y-a-b*x)^2)/n
syx <- sqrt(syx2)
sig2 <- n*syx2/(n-2)
sig <- sqrt(sig2)
sigy2 <- n*sy2/(n-1)
rbar2 <- 1 - (sig2/sigy2)
rbar <- a / (sig*sqrt(n)*1)
####t-value
sx2 <- sum((x-mean(x))^2)/n
sx <- sqrt(sx2)
siga2 <- sig2 * sum(x^2) /(n^2*sx2)
siga <- sqrt(siga2)
sigb2 <- sig2/(n*sx2)
sigb <- sqrt(sigb2)
ta <- a / siga
tb <- b / sigb
####p-value
pa <- (1 - pt(ta, n-2))*2
pb <- (1 - pt(tb, n-2))*2
####Print
print(paste("a=", a))
print(paste("b=", b))
print(paste("rbar2=", rbar2))
print(paste("ta=", ta))
print(paste("tb=", tb))
print(paste("pa=", pa))
print(paste("pb=", pb))
ベイズ統計学入門 [統計学]
■ベイズ統計学を学ぶには
日本でもベイズ統計学に関する本が増えてきました。RやWinBUGSの普及ともにベイズが身近な存在になってきています。しかし、入門書などでは「主観確率」を扱えてビジネスに有用とか書いてありますが、なかなか一般企業でビジネスに使われている状況にはなっていないのではないかと思っています。
その理由はベイズモデルの複雑さ(柔軟さ)にあるのではないかと思います。たとえば、普通のロジットモデルに慣れてしまうと、階層ベイズを使ったロジットモデルを理解するのにちょっとしたハードルがあるように感じられます(少なくとも私はそうでした)。WinBUGSというMCMCサンプラーでモデリングするんだ~というところはなんとなく分かるんですが、モデル式をどのように記述すればいいのかイマイチ想像がつかないのです。
これから紹介する本のようにこのあたりの学習のしづらさを補うものが登場してきましたが、まだまだ入門~中級あたりをサポートする書籍が少ないのが現状のようです。様々なBUGSモデルとRコードを併記したベイズモデルの事例集があると便利と思うのですが、どこかの出版社で企画してくれないかな・・・。
そんなんなこんなで、以下、ベイズ上達のために有用と思う書籍を列挙しようと思います。頻度主義統計学(フツーの統計学)をある程度理解している前提です。小生は頭が良くないのでベイズを理解するのにとても時間がかかりました(今でもちょっと知識があやしい)が、これらの本を組み合わせれば理解が深まることでしょう。
■ベイズを理解する上で有用な和書
")
・この本を久保先生が出版してくれたおかげで初級~入門の知識をさくっと入手できるようになりました。BUGSやRコードも著者サイトからダウンロードできるし言うことなしです。ベイズを勉強しよう!と思ったら必ず入手すべき本です。

・久保先生の本は直観的にベイズを理解できるようになっていますが、理論が手薄です。ベイズ理論の入門はこの本が優れています。頻度主義統計学からベイズ統計学の理論的な架け橋になっています。数式と図のバランスが絶妙です。ただし、この本にはMCMCの記述がないので別の本で勉強する必要ががあるでしょう。
")
・MCMCについては伊庭先生のこの本が決定的に分かりやすいと思います。上記の久保先生の本と合わせれば基礎は十分でしょう。
")
・過去何回か紹介しましたが、この本は名著だと思います。Rコードが豊富です。しかもほとんどパッケージが使われておらず、アルゴリズムがRコードで実装されていますので、コードを解読するとアルゴリズムが理解できます。どちらかというと時系列解析をベイズでやりたい人向けですが、MCMCのサンプルコードも登場するので、階層ベイズに興味がある人にとっても有用と思います。

・石田先生のMCMC本。Rのサンプルコードが豊富な極め付けのような本です。モンテカルロ積分の基礎から収束判定の数式がしっかり書いてあるなどかゆいところに手が届く感じですね。中級~上級者はこの本で勉強するとよいと思います。私もこれからこの本にトライします。
■最後に
日本のベイズ本はWinBUGSでのMCMCを紹介する本が多いのですが、残念ながらWinBUGSは開発がストップしちゃっています。JAGSやSTANなどの代替ツールが登場してきているので、今後はこのようなものが主流になってくるのだと思います。ちなみに、和書ではこれらのツールを詳述するものはありません。体系的な書籍の登場が待たれるところです。
日本でもベイズ統計学に関する本が増えてきました。RやWinBUGSの普及ともにベイズが身近な存在になってきています。しかし、入門書などでは「主観確率」を扱えてビジネスに有用とか書いてありますが、なかなか一般企業でビジネスに使われている状況にはなっていないのではないかと思っています。
その理由はベイズモデルの複雑さ(柔軟さ)にあるのではないかと思います。たとえば、普通のロジットモデルに慣れてしまうと、階層ベイズを使ったロジットモデルを理解するのにちょっとしたハードルがあるように感じられます(少なくとも私はそうでした)。WinBUGSというMCMCサンプラーでモデリングするんだ~というところはなんとなく分かるんですが、モデル式をどのように記述すればいいのかイマイチ想像がつかないのです。
これから紹介する本のようにこのあたりの学習のしづらさを補うものが登場してきましたが、まだまだ入門~中級あたりをサポートする書籍が少ないのが現状のようです。様々なBUGSモデルとRコードを併記したベイズモデルの事例集があると便利と思うのですが、どこかの出版社で企画してくれないかな・・・。
そんなんなこんなで、以下、ベイズ上達のために有用と思う書籍を列挙しようと思います。頻度主義統計学(フツーの統計学)をある程度理解している前提です。小生は頭が良くないのでベイズを理解するのにとても時間がかかりました(今でもちょっと知識があやしい)が、これらの本を組み合わせれば理解が深まることでしょう。
■ベイズを理解する上で有用な和書
データ解析のための統計モデリング入門――一般化線形モデル・階層ベイズモデル・MCMC (確率と情報の科学)
- 作者: 久保 拓弥
- 出版社/メーカー: 岩波書店
- 発売日: 2012/05/19
- メディア: 単行本
・この本を久保先生が出版してくれたおかげで初級~入門の知識をさくっと入手できるようになりました。BUGSやRコードも著者サイトからダウンロードできるし言うことなしです。ベイズを勉強しよう!と思ったら必ず入手すべき本です。
- 作者: 渡部 洋
- 出版社/メーカー: 福村出版
- 発売日: 1999/09
- メディア: 単行本
・久保先生の本は直観的にベイズを理解できるようになっていますが、理論が手薄です。ベイズ理論の入門はこの本が優れています。頻度主義統計学からベイズ統計学の理論的な架け橋になっています。数式と図のバランスが絶妙です。ただし、この本にはMCMCの記述がないので別の本で勉強する必要ががあるでしょう。
計算統計 2 マルコフ連鎖モンテカルロ法とその周辺 (統計科学のフロンティア 12)
- 作者: 伊庭 幸人
- 出版社/メーカー: 岩波書店
- 発売日: 2005/10/27
- メディア: 単行本
・MCMCについては伊庭先生のこの本が決定的に分かりやすいと思います。上記の久保先生の本と合わせれば基礎は十分でしょう。
- 作者: 姜 興起
- 出版社/メーカー: 共立出版
- 発売日: 2010/07/24
- メディア: 単行本
・過去何回か紹介しましたが、この本は名著だと思います。Rコードが豊富です。しかもほとんどパッケージが使われておらず、アルゴリズムがRコードで実装されていますので、コードを解読するとアルゴリズムが理解できます。どちらかというと時系列解析をベイズでやりたい人向けですが、MCMCのサンプルコードも登場するので、階層ベイズに興味がある人にとっても有用と思います。
- 作者: C.P.ロバート
- 出版社/メーカー: 丸善出版
- 発売日: 2012/08/23
- メディア: ムック
・石田先生のMCMC本。Rのサンプルコードが豊富な極め付けのような本です。モンテカルロ積分の基礎から収束判定の数式がしっかり書いてあるなどかゆいところに手が届く感じですね。中級~上級者はこの本で勉強するとよいと思います。私もこれからこの本にトライします。
■最後に
日本のベイズ本はWinBUGSでのMCMCを紹介する本が多いのですが、残念ながらWinBUGSは開発がストップしちゃっています。JAGSやSTANなどの代替ツールが登場してきているので、今後はこのようなものが主流になってくるのだと思います。ちなみに、和書ではこれらのツールを詳述するものはありません。体系的な書籍の登場が待たれるところです。
PythonでMCMC(メトロポリス法)-ベイズ統計学 [統計学]
最近は状態空間モデリングの勉強をしています。その一環できちんとMCMCを理解しようとあれこれ資料を漁っていました。マルコフ連鎖モンテカルロ法を実装してみようというブログ記事や「計算統計 2 マルコフ連鎖モンテカルロ法とその周辺 」などを読みつつ、メトロポリス法というシンプルなMCMCをPythonで実装してみました。
」などを読みつつ、メトロポリス法というシンプルなMCMCをPythonで実装してみました。
■計算条件
・2変量正規分布からサンプリング
【2変量正規分布】
=\frac{1}{Z}exp(-\frac{x_1^2-2bx_1x_2+x_2^2}{2}))

・b = 0.5 (ここでは適当にこの値にした)
・burn-in = 0
-サンプリングの挙動を確認するためバーンインは0とした
■Pythonコード
■結果
・2変量の動き
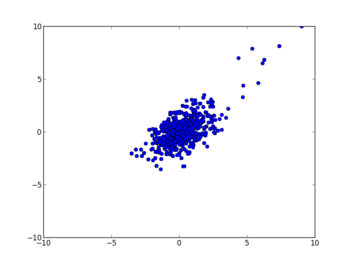
#初期値から数サンプルはふらふらと彷徨うが、しばらくすると最大値付近に収束
・p(x1,x2)の収束状況
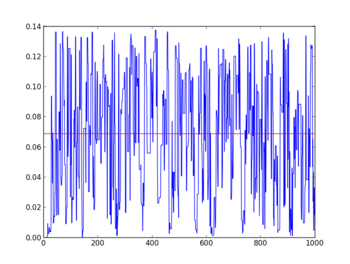
#時系列にグラフ化すると収束性を確認することができる
■感想
・メトロポリス法はとシンプルなアルゴリズムで理解しやすい
・この調子でメトロポリスヘイスティング法とギブスサンプラー法も理解する予定
・GAなんかを併用する手法はないのかな?
■参考文献
・伊庭先生の解説が一番分かりやすいと思う。これが少し難易度が高いなら久保先生のベイズ本 などを最初に読むといいです
などを最初に読むといいです
・あんまり注目されていないような気がするんだけど、この本も名著です。MCMCのRコードもあります。状態空間モデルのRコードはとても重宝しています。北川先生の時系列本 と合わせて読むと理解がより深まりますね!
と合わせて読むと理解がより深まりますね!
■計算条件
・2変量正規分布からサンプリング
【2変量正規分布】
・b = 0.5 (ここでは適当にこの値にした)
・burn-in = 0
-サンプリングの挙動を確認するためバーンインは0とした
■Pythonコード
#!/usr/bin/env python
#-*- coding:utf-8 -*-
import math
import random
import numpy as np
import matplotlib.pyplot as plt
def metropolis(func, start=10.0, delta=2.0, burn_in=0, seed=1):
metro_iter = _metropolis(func, start, delta, seed)
for i, value in enumerate(metro_iter):
if i > burn_in:
yield value
break
for value in metro_iter:
yield value
def _metropolis(func, start, delta, seed):
random.seed(seed)
initial_x1 = start
initial_x2 = start
initial_fx = func(initial_x1, initial_x2)
proposed_x1, proposed_x2, proposed_fx = 0.0, 0.0, 0.0
for j in range(1,1000):
proposed_x1 = initial_x1 + random.uniform(-delta, delta)
proposed_x2 = initial_x2 + random.uniform(-delta, delta)
proposed_fx = func(proposed_x1, proposed_x2)
ratio = proposed_fx / initial_fx
if ratio > 1.0 or ratio > random.random():
initial_x1, initial_x2, initial_fx = proposed_x1, proposed_x2, proposed_fx
yield proposed_x1, proposed_x2, proposed_fx
else:
yield initial_x1, initial_x2, initial_fx
def main():
b = 0.5
Z = 2*math.pi/math.sqrt(1.0-b**2.0)
f = lambda x1, x2: math.exp(-(x1**2-2*b*x1*x2+x2**2)/2)/Z
xb1 = []
xb2 = []
fxb1 = []
for x1, x2, fx in metropolis(f):
xb1.append(x1)
xb2.append(x2)
fxb1.append(fx)
tx = range(1,len(fxb1)+1)
md = [np.median(fxb1)]*(len(fxb1))
plt.plot(xb1,xb2,"bo")
plt.axis([-10, 10, -10, 10])
plt.show()
plt.plot(tx, fxb1)
plt.plot(tx, md, "r")
plt.axis([0, 1000, 0, 0.14])
plt.show()
if __name__ == '__main__':
main()
■結果
・2変量の動き
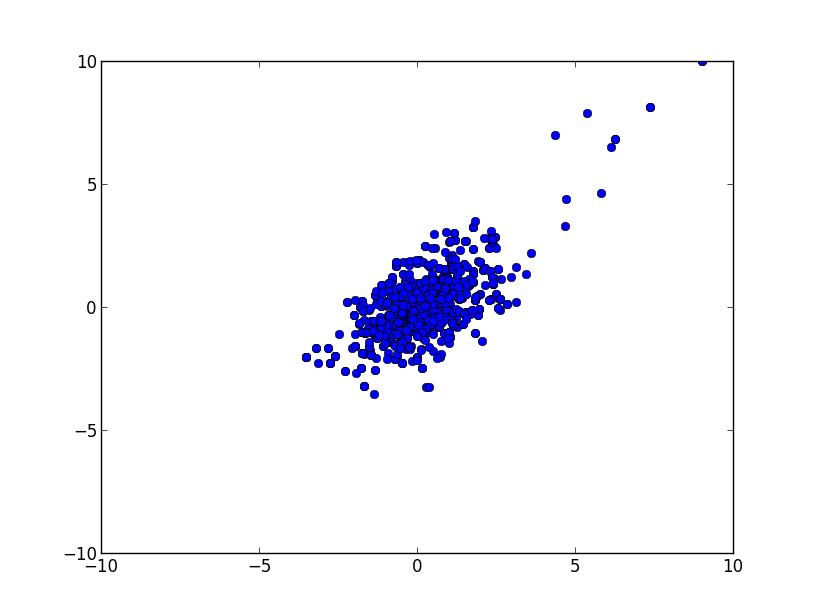
#初期値から数サンプルはふらふらと彷徨うが、しばらくすると最大値付近に収束
・p(x1,x2)の収束状況
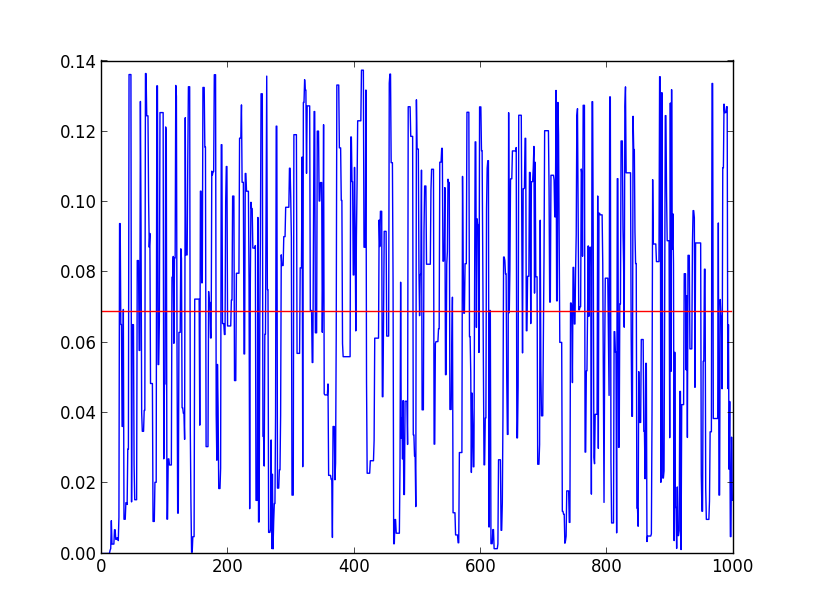
#時系列にグラフ化すると収束性を確認することができる
■感想
・メトロポリス法はとシンプルなアルゴリズムで理解しやすい
・この調子でメトロポリスヘイスティング法とギブスサンプラー法も理解する予定
・GAなんかを併用する手法はないのかな?
■参考文献
計算統計 2 マルコフ連鎖モンテカルロ法とその周辺 (統計科学のフロンティア 12)
- 作者: 伊庭 幸人
- 出版社/メーカー: 岩波書店
- 発売日: 2005/10/27
- メディア: 単行本
・伊庭先生の解説が一番分かりやすいと思う。これが少し難易度が高いなら久保先生のベイズ本
- 作者: 姜 興起
- 出版社/メーカー: 共立出版
- 発売日: 2010/07/24
- メディア: 単行本
・あんまり注目されていないような気がするんだけど、この本も名著です。MCMCのRコードもあります。状態空間モデルのRコードはとても重宝しています。北川先生の時系列本
データ分析上達法②「データ分析と社会人大学院」-データサイエンティストを目指して(4) [データサイエンティスト]
前回の記事でデータ分析を身に着けるための手段として、①Rを独学で身に着ける、②社会人大学院に入学する、③データ分析専門企業に転職する。という3つを提案しました。今回は「②社会人大学院に入学する」について書いてみようと思います。
Rなどのフリーで高度なツールがある今では頑張れば独学でデータ分析技術を習得することができると思います。ただ、忙しい社会人がゼロから独学で勉強して身に着けるというは大変なことではあります。どうせ頑張らないといけないならもっと手っ取り早くかつ本格的に学べる方法はないかというと、その一つが大学院に通うという方法になります。大学院以外にもEMCが開催しているデータサイエンティスト育成トレーニングコースというものがあるらしいですが、今回の主題はあくまでも「社会人大学院」です。
私は社会人大学院の出身です。数年前に「筑波大学ビジネス科学研究科経営システム科学専攻」(通称:GSSM)というところを修了しました。なので、この大学院については詳しく紹介することができます。この大学院は茨城県つくば市にあるわけではなく、東京の茗荷谷にあります。また、平日夜間と土曜日に講義やゼミが開催されるので都心に勤務しているビジネスマンが会社勤務を続けながら専門的な学識を深めることができ、修士号(MBA)や博士号まで取得することができます。おまけに国立なので授業料も私立に比べれば格段に安価です(2年間で130万円程度)。
この大学院のコンセプトは「経営・数理・ITの融合教育」です。戦略論やマーケティングなどの経営学、統計学や最適化などの数理的な手法、そしてプログラミングやデータベースなどのIT技術をバランスよく学ぶことができます。修士課程では修士論文が修了条件に課せられており、アカデミックな色彩が強い大学院です。MBAを標榜していますが、ケースの読み込みとディスカッション中心の一般的なMBAとは異なり、アカデミックにきちんとした論文を作成しないと修了できません。論文指導は3人の指導教官により行われます。通常、この3人は別々の分野の教官となりますから、学際的な色彩の強い社会人の研究に対応した指導体制と言うことができます。
この修士論文の作成には非常に苦労するわけですが、これが何とも他では得られない学びの場になります。自前のデータを持ち込み、又は自分でデータを収集した上で、RやSPSSの分析ツールをバリバリ使って研究を行うことになります。また、スパルタな先生もおり、生半可な分析では修了させてももらえません。分析しながら深く思考してそれを論文として表現する訓練を積むことになります。このような環境ですから、分析ツールなどに触ったことがなかった人でも2年間で分析を使いこなし知識を獲得し表現する手段を嫌というほど頭と体に刷り込むことができます。
30人の少人数教育なので学生間のコミュニケーションも非常に濃密です。多様なジャンルの職場で働いている人たちなので自分の専門外のことを同級生から学ぶことができます。統計学のスペシャリストが経営を学ぶために来ていたりするので、RやSPSSについては既にプロレベルという人も少なくありません。分析手法で分からないことがあれば、プロの同級生に相談することが容易にできます。統計学やプログラミングなどの実務知識の学習は詳しい人が近くにいると非常に捗るので、これはとても恵まれた学習環境です。
また、この大学院の本質は分析ツールの小手先のテクニックを学べることにあるわけではなく、「本当の問題とは何か?」ということを深く考えて、これを解決するための手段を自分と教官の共同作業で追及していくことにあります。データサイエンティストの文脈ではRやHadoopなどのキーワードに踊らされている感がありますが、このようなツールは時代とともに変遷していきます。本当に身に着けるべきことは問題発見能力と問題解決能力です。たとえRやSPSSが上手いデータサイエンティストでもこれらの能力が備わっていなければ、現在の流行が去るのと同時に役に立たない人材になってしまうと思います。
欧米では社会人教育が充実しているのでビジネスで必要なことを在職しながら大学で学ぶことができます。しかし、日本ではまだ大学での社会人教育が浸透しているわけではありません。データサイエンスを身に着けて活躍したい人が社会人大学院で学ぼうとすると適した大学が非常に少ないのが現状です。GSSMは本格的なデータサイエンティストの育成に適した現行では日本唯一の社会人大学院と言えるでしょう。
GSSMは入試倍率が比較的高いのでそれなりに準備が必要です。とはいうものの、昔みたいに倍率10倍ということはなく3~4倍といったところなのできちんと対策を立てれば合格できます。入試では研究計画書が要になるので、アカデミックスタイルで書き上げる必要があります。入試対策についてはググればいろいろ出てきますのでここでは触れません。ちなみに、私は以下の本で勉強しました。
■参考文献
")
・知財界隈でも有名な妹尾先生の本です。研究計画書の実例とそれに対する先生のコメントがとても参考になりました。社会人大学院に限定されていませんが、GSSMはアカデミックスタイルなのでこの本にあるような内容は踏襲しておく必要があるでしょう。

・こちらはMBA対策本です。GSSMの事例も掲載されているので参考になると思います。
Rなどのフリーで高度なツールがある今では頑張れば独学でデータ分析技術を習得することができると思います。ただ、忙しい社会人がゼロから独学で勉強して身に着けるというは大変なことではあります。どうせ頑張らないといけないならもっと手っ取り早くかつ本格的に学べる方法はないかというと、その一つが大学院に通うという方法になります。大学院以外にもEMCが開催しているデータサイエンティスト育成トレーニングコースというものがあるらしいですが、今回の主題はあくまでも「社会人大学院」です。
私は社会人大学院の出身です。数年前に「筑波大学ビジネス科学研究科経営システム科学専攻」(通称:GSSM)というところを修了しました。なので、この大学院については詳しく紹介することができます。この大学院は茨城県つくば市にあるわけではなく、東京の茗荷谷にあります。また、平日夜間と土曜日に講義やゼミが開催されるので都心に勤務しているビジネスマンが会社勤務を続けながら専門的な学識を深めることができ、修士号(MBA)や博士号まで取得することができます。おまけに国立なので授業料も私立に比べれば格段に安価です(2年間で130万円程度)。
この大学院のコンセプトは「経営・数理・ITの融合教育」です。戦略論やマーケティングなどの経営学、統計学や最適化などの数理的な手法、そしてプログラミングやデータベースなどのIT技術をバランスよく学ぶことができます。修士課程では修士論文が修了条件に課せられており、アカデミックな色彩が強い大学院です。MBAを標榜していますが、ケースの読み込みとディスカッション中心の一般的なMBAとは異なり、アカデミックにきちんとした論文を作成しないと修了できません。論文指導は3人の指導教官により行われます。通常、この3人は別々の分野の教官となりますから、学際的な色彩の強い社会人の研究に対応した指導体制と言うことができます。
この修士論文の作成には非常に苦労するわけですが、これが何とも他では得られない学びの場になります。自前のデータを持ち込み、又は自分でデータを収集した上で、RやSPSSの分析ツールをバリバリ使って研究を行うことになります。また、スパルタな先生もおり、生半可な分析では修了させてももらえません。分析しながら深く思考してそれを論文として表現する訓練を積むことになります。このような環境ですから、分析ツールなどに触ったことがなかった人でも2年間で分析を使いこなし知識を獲得し表現する手段を嫌というほど頭と体に刷り込むことができます。
30人の少人数教育なので学生間のコミュニケーションも非常に濃密です。多様なジャンルの職場で働いている人たちなので自分の専門外のことを同級生から学ぶことができます。統計学のスペシャリストが経営を学ぶために来ていたりするので、RやSPSSについては既にプロレベルという人も少なくありません。分析手法で分からないことがあれば、プロの同級生に相談することが容易にできます。統計学やプログラミングなどの実務知識の学習は詳しい人が近くにいると非常に捗るので、これはとても恵まれた学習環境です。
また、この大学院の本質は分析ツールの小手先のテクニックを学べることにあるわけではなく、「本当の問題とは何か?」ということを深く考えて、これを解決するための手段を自分と教官の共同作業で追及していくことにあります。データサイエンティストの文脈ではRやHadoopなどのキーワードに踊らされている感がありますが、このようなツールは時代とともに変遷していきます。本当に身に着けるべきことは問題発見能力と問題解決能力です。たとえRやSPSSが上手いデータサイエンティストでもこれらの能力が備わっていなければ、現在の流行が去るのと同時に役に立たない人材になってしまうと思います。
欧米では社会人教育が充実しているのでビジネスで必要なことを在職しながら大学で学ぶことができます。しかし、日本ではまだ大学での社会人教育が浸透しているわけではありません。データサイエンスを身に着けて活躍したい人が社会人大学院で学ぼうとすると適した大学が非常に少ないのが現状です。GSSMは本格的なデータサイエンティストの育成に適した現行では日本唯一の社会人大学院と言えるでしょう。
GSSMは入試倍率が比較的高いのでそれなりに準備が必要です。とはいうものの、昔みたいに倍率10倍ということはなく3~4倍といったところなのできちんと対策を立てれば合格できます。入試では研究計画書が要になるので、アカデミックスタイルで書き上げる必要があります。入試対策についてはググればいろいろ出てきますのでここでは触れません。ちなみに、私は以下の本で勉強しました。
■参考文献
研究計画書の考え方―大学院を目指す人のために (DIAMOND EXECUTIVE DATA BOOK)
- 作者: 妹尾 堅一郎
- 出版社/メーカー: ダイヤモンド社
- 発売日: 1999/03
- メディア: 単行本
・知財界隈でも有名な妹尾先生の本です。研究計画書の実例とそれに対する先生のコメントがとても参考になりました。社会人大学院に限定されていませんが、GSSMはアカデミックスタイルなのでこの本にあるような内容は踏襲しておく必要があるでしょう。
- 作者: 飯野 一
- 出版社/メーカー: 中央経済社
- 発売日: 2003/07
- メディア: 単行本
・こちらはMBA対策本です。GSSMの事例も掲載されているので参考になると思います。
データ分析上達法①「Rで分析を始めよう!」-データサイエンティストを目指して(3) [データサイエンティスト]
データ分析上達法①「Rで分析を始めよう!」-データサイエンティストを目指して(3)
多くの企業でデータ分析のニーズが増大していますが、データサイエンティストと呼ばれるプロフェッショナルは希少であり、なかなか採用するのは難しいらしいです。じゃあ、どうすればいいのか?
なんのことはありません。
自分で初めてしまえばいいのです。
Excelしか使ったことがないし。文系だし。とかいう意見が聞こえてきそうですが、今のスペックはあまり関係ないです。要はやる気です。スキマ時間を使ってデータ分析の練習をすれば誰でもある程度の分析スキルを身に着けることができると思います。
ビッグデータという波に乗っているデータ分析専門の会社でデータサイエンティストという肩書を名乗っている人でも、大学で統計学や情報工学を専攻した人ばかりではありません。むしろ、事業会社でマーケティングや営業をやっていた人も少なくないのです。つまり専門教育を受けてない人でも訓練を受け、研鑽に励めば価値のあるコンサルテーションができるレベルになれる。それがデータ分析です。
では、どのようにすればてっとりばやくデータ分析を身に着けられるのか?
本稿では次の、①Rを独学で身に着ける、②社会人大学院に入学する、③データ分析専門企業に転職する。という3つのソリューションを提案したいと思います。今日は①について書きます。
①Rを独学で身に着ける
先ずやらなければならないことはExcelを卒業することです。Excelにも回帰分析などの統計分析機能が実装されていますが、機能が非常に限られています。なので、ちょっと高度なことをやろうとExcelではすぐに限界を迎えます。
そこで、R です。
Rというのはデータを分析するためのソフトウェアです。すごく高機能ですが、なんとフリーです。ダウンロードしてPCにインストールすればすぐにでも動きます。回帰分析もクラスタリングもタダで実行できます。
ただし、プログラミングを経験したことのない人にとっては若干敷居が高いでしょう。しかし、頑張って一度習得してしまえば様々な可能性が開けます。GUIのSPSSなどが手元にあるならばそこからスタートでもいいのですが、結局あれこれ深いことをやろうとするとGUIでは必ず物足りなくなります。初めからRと向かい合う方が結局は近道だと思います。
そうはいっても何もデータ分析について知らない人が突然Rというのも酷な話かもしれません。そこで、R勉強会というものに参加することをお薦めします。データ分析やプログラミングの勉強をする時には近くに詳しい人がいると非常に効率的に身に着けられます。分からないことを長時間かけてGoogleで調べるよりもこのような会で上手く知り合いを作ってしまうのがはるかに近道でしょう。
また、後ほど紹介しますが、Rは世界各国で使われているので書籍が非常に豊富です。入門者のための書籍も当然充実しています。怖がらずに初めてみましょう。案ずるより産むがやすしというのがデータ分析です。
◆データ分析入門者のためのR本

・Rstudioという便利な統合環境に初めから慣れてしまったほうがいいです。最新バージョンはずいぶん使いやすくなりました。これを使うとナイーブなRを使うことはあまりなくなります。この本は初歩の初歩からRについて解説されているので、思い立ったまずこの本でしょう。

・以前にも紹介しましたが、この本は良い本です。統計学から機械学習までさまざまな手法が紹介されています。R入門者でも持っていると視野が広がると思います。

・辞書はこれがベストですね。コーディングの基礎から応用まで幅広く記載があります。手元に置きながらRを試すと上達が早いと思います。RStudioと同じ著者です。石田先生の本は良い本が多い気がします
◆関連記事
データサイエンティストの教養(ビジネス編)-データサイエンティストを目指して(2)
勇気を出して初めてのデータ分析 - データサイエンティストを目指して(1)
多くの企業でデータ分析のニーズが増大していますが、データサイエンティストと呼ばれるプロフェッショナルは希少であり、なかなか採用するのは難しいらしいです。じゃあ、どうすればいいのか?
なんのことはありません。
自分で初めてしまえばいいのです。
Excelしか使ったことがないし。文系だし。とかいう意見が聞こえてきそうですが、今のスペックはあまり関係ないです。要はやる気です。スキマ時間を使ってデータ分析の練習をすれば誰でもある程度の分析スキルを身に着けることができると思います。
ビッグデータという波に乗っているデータ分析専門の会社でデータサイエンティストという肩書を名乗っている人でも、大学で統計学や情報工学を専攻した人ばかりではありません。むしろ、事業会社でマーケティングや営業をやっていた人も少なくないのです。つまり専門教育を受けてない人でも訓練を受け、研鑽に励めば価値のあるコンサルテーションができるレベルになれる。それがデータ分析です。
では、どのようにすればてっとりばやくデータ分析を身に着けられるのか?
本稿では次の、①Rを独学で身に着ける、②社会人大学院に入学する、③データ分析専門企業に転職する。という3つのソリューションを提案したいと思います。今日は①について書きます。
①Rを独学で身に着ける
先ずやらなければならないことはExcelを卒業することです。Excelにも回帰分析などの統計分析機能が実装されていますが、機能が非常に限られています。なので、ちょっと高度なことをやろうとExcelではすぐに限界を迎えます。
そこで、R です。
Rというのはデータを分析するためのソフトウェアです。すごく高機能ですが、なんとフリーです。ダウンロードしてPCにインストールすればすぐにでも動きます。回帰分析もクラスタリングもタダで実行できます。
ただし、プログラミングを経験したことのない人にとっては若干敷居が高いでしょう。しかし、頑張って一度習得してしまえば様々な可能性が開けます。GUIのSPSSなどが手元にあるならばそこからスタートでもいいのですが、結局あれこれ深いことをやろうとするとGUIでは必ず物足りなくなります。初めからRと向かい合う方が結局は近道だと思います。
そうはいっても何もデータ分析について知らない人が突然Rというのも酷な話かもしれません。そこで、R勉強会というものに参加することをお薦めします。データ分析やプログラミングの勉強をする時には近くに詳しい人がいると非常に効率的に身に着けられます。分からないことを長時間かけてGoogleで調べるよりもこのような会で上手く知り合いを作ってしまうのがはるかに近道でしょう。
また、後ほど紹介しますが、Rは世界各国で使われているので書籍が非常に豊富です。入門者のための書籍も当然充実しています。怖がらずに初めてみましょう。案ずるより産むがやすしというのがデータ分析です。
◆データ分析入門者のためのR本
Rで学ぶデータ・プログラミング入門 ―RStudioを活用する―
- 作者: 石田 基広
- 出版社/メーカー: 共立出版
- 発売日: 2012/10/24
- メディア: 単行本
・Rstudioという便利な統合環境に初めから慣れてしまったほうがいいです。最新バージョンはずいぶん使いやすくなりました。これを使うとナイーブなRを使うことはあまりなくなります。この本は初歩の初歩からRについて解説されているので、思い立ったまずこの本でしょう。
Rによるデータサイエンス - データ解析の基礎から最新手法まで
- 作者: 金 明哲
- 出版社/メーカー: 森北出版
- 発売日: 2007/10/13
- メディア: 単行本(ソフトカバー)
・以前にも紹介しましたが、この本は良い本です。統計学から機械学習までさまざまな手法が紹介されています。R入門者でも持っていると視野が広がると思います。
- 作者: 石田基広
- 出版社/メーカー: シーアンドアール研究所
- 発売日: 2012/01/26
- メディア: 単行本(ソフトカバー)
・辞書はこれがベストですね。コーディングの基礎から応用まで幅広く記載があります。手元に置きながらRを試すと上達が早いと思います。RStudioと同じ著者です。石田先生の本は良い本が多い気がします
◆関連記事
データサイエンティストの教養(ビジネス編)-データサイエンティストを目指して(2)
勇気を出して初めてのデータ分析 - データサイエンティストを目指して(1)
データ解析のための統計モデリング入門 [統計学]
データ解析のための統計モデリング入門――一般化線形モデル・階層ベイズモデル・MCMC (確率と情報の科学)
- 作者: 久保 拓弥
- 出版社/メーカー: 岩波書店
- 発売日: 2012/05/19
- メディア: 単行本
北大の久保先生のベイズ本を読みました。感想を書きます。
結論から言うと、これは良書です。図が豊富かつ分かりやすい文体なので初学者でもベイズのイメージを頭に浸透させることができるでしょう。そして、GLM(一般化線形モデル)から順を追って解説されているため、伝統的(頻度主義)な統計学にしか知らなくてもベイズの考え方に無理なく馴染むことができます。
久保先生が生態学のご専門なので、サンプルデータは植物の種子数など生態学系のものになりますが、「まえがき」にあるように専門外の人でも全く問題なく読むことができます。そして、生態学における「個体差」や「場所差」はビジネス的にはマーケティングに通じる考え方です。個体差 = 顧客異質性 ⇒ One to One マーケティング というわけです。
マーケティングを題材としたベイズ本もいくつか出版されていますが、ここまで分かりやすいものは残念ながらマーケティング分野にはないと思います。佐藤先生の「ビッグデータ時代のマーケティング―ベイジアンモデリングの活用 (KS社会科学専門書)
最後に、この本ではWinBugsというMCMCサンプラーが使われていますが、このソフトウェアは開発が停止しているようです。開発が現在でも継続しているものにJAGSやStanなどがあるようですが、これらに関する記載は本書にはありません。JAGSについては解説がある洋書は見つかりましたが、Stanについては今のところGoogle先生だけが頼みのようです。
◆参考文献
■ビッグデータ時代のマーケティング
ビッグデータ時代のマーケティング―ベイジアンモデリングの活用 (KS社会科学専門書)
- 作者: 佐藤 忠彦
- 出版社/メーカー: 講談社
- 発売日: 2013/01/22
- メディア: 単行本(ソフトカバー)
・GSSMの佐藤先生の本です。以前の記事でも紹介しましたが、マーケティングのベイズ本として非常に分かりやすいです。階層ベイズから粒子フィルターの適用まで最新のマーケティングサイエンスの技術が紹介されています。
■Doing Bayesian Data Analysis: A Tutorial Introduction with R

Doing Bayesian Data Analysis: A Tutorial Introduction with R
- 作者: John Kruschke
- 出版社/メーカー: Academic Press
- 発売日: 2010/11/10
- メディア: ハードカバー
・久保先生の本には記述がないJAGSについてはこちらの本がよさそうです。まだ持っていないのでなんとも言えませんが、Amazon.comの評価がものすごく良いのでとても気になっています。
前の10件 | -