パトリック・シルベストル さん




Rによる隠れマルコフモデル [R]
大学院のゼミでPRML を読んでいる。私の担当は13章「系列データ」の後半の「状態空間モデル」(SSM: State Space Model)である。13章の前半は「隠れマルコフモデル」(HMM: Hidden Markov Model)について記述されている。SSMは日本のお家芸であり、統計数理研究所の先代所長の北川先生や現所長の樋口先生により発展した。ところが、SSMの離散バージョンだと言われているHMMはなぜかあまり日本ではクローズアップされていない。PRMLはHMM→SSMの順番で記述されているので、丁度良い機会だからついでにHMMについて勉強しようと思ってこのブログをアップした。
を読んでいる。私の担当は13章「系列データ」の後半の「状態空間モデル」(SSM: State Space Model)である。13章の前半は「隠れマルコフモデル」(HMM: Hidden Markov Model)について記述されている。SSMは日本のお家芸であり、統計数理研究所の先代所長の北川先生や現所長の樋口先生により発展した。ところが、SSMの離散バージョンだと言われているHMMはなぜかあまり日本ではクローズアップされていない。PRMLはHMM→SSMの順番で記述されているので、丁度良い機会だからついでにHMMについて勉強しようと思ってこのブログをアップした。
とりあえず、はじめからアルゴリズムを実装するのは私の実力では厳しいので、Rのパッケージで遊んでみよう思ってあれこれ探したところ、{RHmm}というパッケージが見つかった。このパッケージについてはいくつかの日本語ブログで言及されているものの、既にCRANから削除されてしまっている。なんじゃ。と思い、いろいろ調べてみると、{depmixS4}というHMMのパッケージが見つかった。これは最近でも更新されているし、R-bloggerでも紹介されているので間違いないと思って、こちらをいじってみることにした。
(本記事では理論については書いていない。理論について知りたい方はPRML等を参照のこと。)
このパッケージにはSpeedというサンプルデータがあって、これを基にサンプルコードが展開されている。ヘルプには詳しく書かれていなかったが、どうやら心理学のスピードと正確性のトレードオフに関する実験データのようである。
■Speedデータ
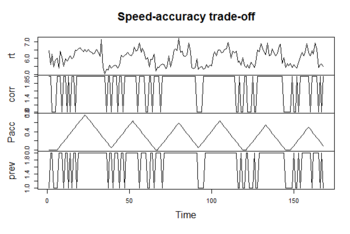
■Rコード
次のコードによりパッケージを読み込んでSpeedデータを可視化する。
次に隠れマルコフモデルを構築する。手始めに隠れ状態 = 2 と想定する。隠れ状態は恣意的に設定するが、AICやBICを参照することで最適な隠れ状態を設定することが可能であるっぽい(勉強中)。以下のコードにて、depmixオブジェクトを作って、EMアルゴリズムでパラメータを推定。
次にモデル推定結果を出力。先ずは情報量の確認。
ちなみに、隠れ状態 = 1 の場合には、AIC = 614.6619, BIC = 622.8309 となることから、上記の隠れ状態 = 2 の方がAICもBICも低いため良いモデルという評価となった。次に推定されたパラメータを確認。
Transition matrixを見ると、推移確率は以下のように推定されたということ。
S1⇒S1: 0.9156683
S1⇒S2: 0.08433171
S2⇒S2: 0.1164891
S2⇒S1: 0.88351091
次に、"Response parameters"の解釈だが、これはおそらく推定された各隠れ状態(S1・S2)におけるレスポンス時間(rt)の平均と分散を記述していると思われる(勉強中のため断言できず)。
最後に、Viterbiアルゴリズムによって潜在変数系列を推定した上で結果を可視化すると次のようになる。
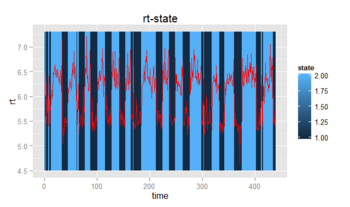
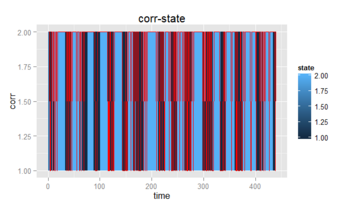
レスポンス時間が落ちていて、かつ誤答が多い部分が認識されていることが分かります。このように隠れマルコフモデルを用いることで、時系列データを離散分離することができるようです。未だ勉強始めたばかりでわからないことだらけですが、そのうちまた続編を書きたいと思います。
■参考文献
")
やっぱりこれが日本語で読める一番詳しい本です。状態空間モデルとの関係が分かりやすいです。
")
洋書ですがRコードが開示されていて分かりやすいです。具体的事例もいくつかあります。
とりあえず、はじめからアルゴリズムを実装するのは私の実力では厳しいので、Rのパッケージで遊んでみよう思ってあれこれ探したところ、{RHmm}というパッケージが見つかった。このパッケージについてはいくつかの日本語ブログで言及されているものの、既にCRANから削除されてしまっている。なんじゃ。と思い、いろいろ調べてみると、{depmixS4}というHMMのパッケージが見つかった。これは最近でも更新されているし、R-bloggerでも紹介されているので間違いないと思って、こちらをいじってみることにした。
(本記事では理論については書いていない。理論について知りたい方はPRML
このパッケージにはSpeedというサンプルデータがあって、これを基にサンプルコードが展開されている。ヘルプには詳しく書かれていなかったが、どうやら心理学のスピードと正確性のトレードオフに関する実験データのようである。
■Speedデータ
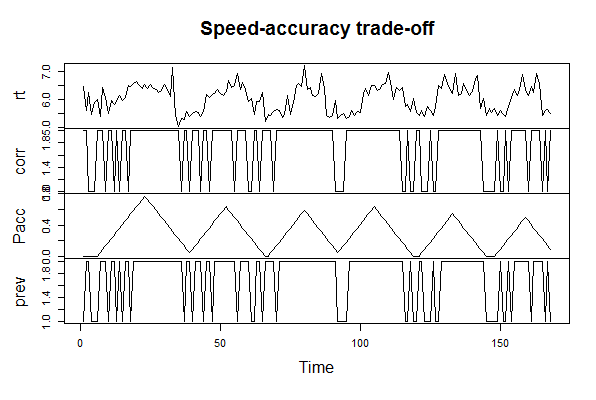
rt: レスポンス時間(response time)
corr: 正答スコア(1/0) (accuracy scores)
pacc: 正確性に注意を払っている度合い (the pay-off for accuracy)
prev: 1期前の正答スコア(1/0) (accuracy scores (0/1) on the previous trial)
■Rコード
次のコードによりパッケージを読み込んでSpeedデータを可視化する。
#####Library library(depmixS4) #####Data data(speed) #####Visualization plot(as.ts(speed[1:168,]), main = "Speed-accuracy trade-off")
次に隠れマルコフモデルを構築する。手始めに隠れ状態 = 2 と想定する。隠れ状態は恣意的に設定するが、AICやBICを参照することで最適な隠れ状態を設定することが可能であるっぽい(勉強中)。以下のコードにて、depmixオブジェクトを作って、EMアルゴリズムでパラメータを推定。
##### Modeling set.seed(1) mod <- depmix(response = rt ~ 1, data = speed, nstates = 2, trstart = runif(4)) fm <- fit(mod) #EMアルゴリズムによるパラメータ推定
次にモデル推定結果を出力。先ずは情報量の確認。
print(fm) # Convergence info: Log likelihood converged to within tol. (relative change) # 'log Lik.' -88.73058 (df=7) # AIC: 191.4612 # BIC: 220.0527
ちなみに、隠れ状態 = 1 の場合には、AIC = 614.6619, BIC = 622.8309 となることから、上記の隠れ状態 = 2 の方がAICもBICも低いため良いモデルという評価となった。次に推定されたパラメータを確認。
summary(fm) # Initial state probabilties model # pr1 pr2 # 1 0 # # # Transition matrix # toS1 toS2 # fromS1 0.9156683 0.08433171 # fromS2 0.1164891 0.88351091 # # Response parameters # Resp 1 : gaussian # Re1.(Intercept) Re1.sd # St1 6.385053 0.2441601 # St2 5.510363 0.1917513
Transition matrixを見ると、推移確率は以下のように推定されたということ。
S1⇒S1: 0.9156683
S1⇒S2: 0.08433171
S2⇒S2: 0.1164891
S2⇒S1: 0.88351091
次に、"Response parameters"の解釈だが、これはおそらく推定された各隠れ状態(S1・S2)におけるレスポンス時間(rt)の平均と分散を記述していると思われる(勉強中のため断言できず)。
最後に、Viterbiアルゴリズムによって潜在変数系列を推定した上で結果を可視化すると次のようになる。
##### Viterbiアルゴリズムによる系列推定
result <- posterior(fm)
result$rt <- speed$rt
result$time <- seq(1,439)
#rt-state
gg1 <- ggplot(data=result,aes(x=time, y=rt)) +
geom_rect(aes(fill = state, xmin = time - 0.5, xmax = time + 0.5, ymin=4.5,
ymax = max(rt) + 0.1)) +
geom_line(colour="red", size=0.5)
print(gg1)
#corr-state
gg2 <- ggplot(data=result,aes(x=time, y=corr)) +
geom_rect(aes(fill = state, xmin = time - 0.5, xmax = time + 0.5, ymin=1.0,
ymax = 2.0)) +
geom_line(colour="red", size=0.5)
print(gg2)
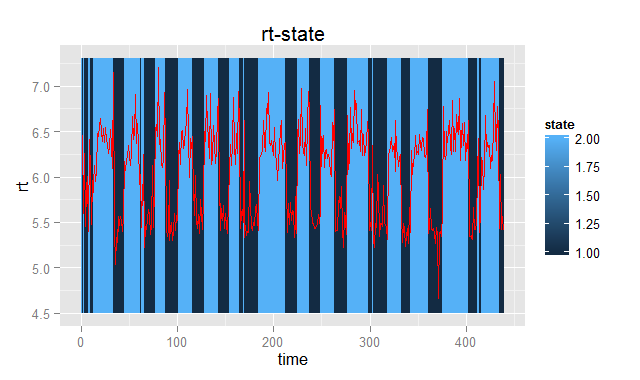
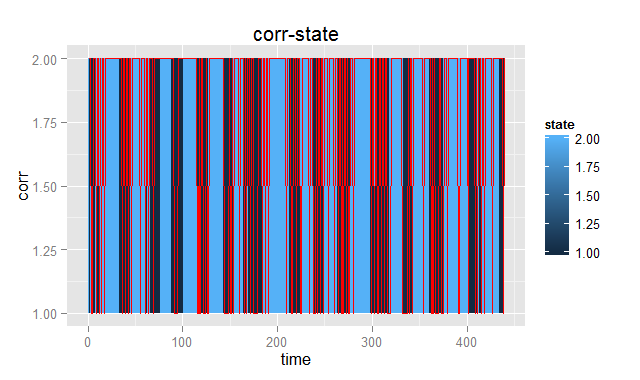
レスポンス時間が落ちていて、かつ誤答が多い部分が認識されていることが分かります。このように隠れマルコフモデルを用いることで、時系列データを離散分離することができるようです。未だ勉強始めたばかりでわからないことだらけですが、そのうちまた続編を書きたいと思います。
■参考文献
- 作者: C.M. ビショップ
- 出版社/メーカー: 丸善出版
- 発売日: 2012/02/29
- メディア: 単行本
やっぱりこれが日本語で読める一番詳しい本です。状態空間モデルとの関係が分かりやすいです。
- 作者: Walter Zucchini
- 出版社/メーカー: Chapman and Hall/CRC
- 発売日: 2009/04/30
- メディア: ハードカバー
洋書ですがRコードが開示されていて分かりやすいです。具体的事例もいくつかあります。
2015-04-23 08:07
nice!(0)
コメント(1)
トラックバック(0)
知財×データサイエンスに興味があるので、このブログとても楽しいですね!今も知財分野でデータ分析やられているのでしょうか?
by たか (2016-02-20 17:31)