パトリック・シルベストル さん




バランスサンプリング(Cube法) [統計学]
効果的なサンプリング(標本抽出)について調べていたところ、バランスサンプリング(Cube法)という方法が良いらしいので早速試してみた。iAnalysisさんのブログ「調査のためのサンプリング」を参考にした。
■実験条件
1.データ
・MU284(アイスランドのデータ(税収、党の議席数など)-284件
2.R Package
sampling package
3.比較
①Balanced SamplingとRandom Samplingについて変数:RMT85のHorvitz-Thompson推定量と全体合計との比較
②Balanced SamplingとRandom Samplingについてboxplotで比較
4.結果
①Horvitz-Thompson推定量と全体合計との比較
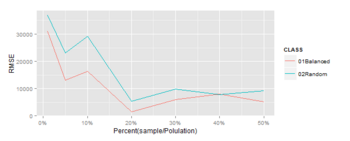
※Horvitz-Thompson推定量と全体合計のRMSEをプロット(この方法で検証あってるかちょっと不安)
②boxplotで比較
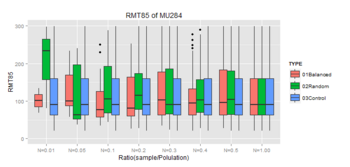
※Controlは母集団のBoxplot
★このデータの場合、バランスサンプリングは10%程度のサンプルで母集団との類似性が大きくなってきている。効果ありそう。もうちょっと調べてみようと思う。
6.コード
■参考文献
・概説 標本調査法 (統計ライブラリー)
")
cube法について書かれている和書はなさそうですが、標本調査の基礎にいてはこの本がわりと分かりやすいです。
・Sampling Algorithms (Springer Series in Statistics)
")
cube法について詳しく書いてあるのはこの本みたいです。本当にちゃんとやろうとすると洋書になっちゃうんですよね。やっぱり学者の層が薄いのでしょうか。いずれ読まなきゃなこの本。
■実験条件
1.データ
・MU284(アイスランドのデータ(税収、党の議席数など)-284件
2.R Package
sampling package
3.比較
①Balanced SamplingとRandom Samplingについて変数:RMT85のHorvitz-Thompson推定量と全体合計との比較
②Balanced SamplingとRandom Samplingについてboxplotで比較
4.結果
①Horvitz-Thompson推定量と全体合計との比較
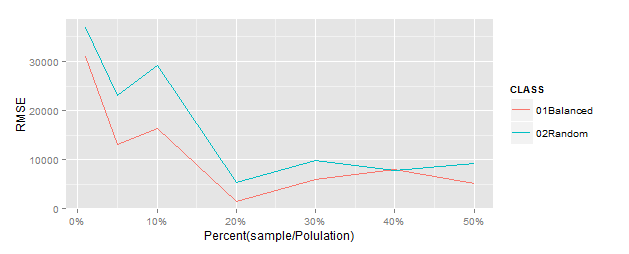
※Horvitz-Thompson推定量と全体合計のRMSEをプロット(この方法で検証あってるかちょっと不安)
②boxplotで比較
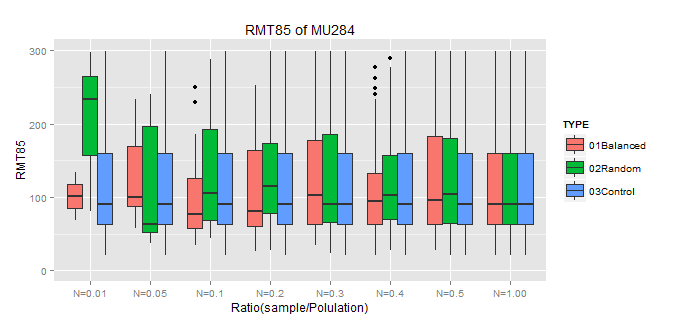
※Controlは母集団のBoxplot
★このデータの場合、バランスサンプリングは10%程度のサンプルで母集団との類似性が大きくなってきている。効果ありそう。もうちょっと調べてみようと思う。
6.コード
####ライブラリ
library(sampling)
library(ggplot2)
library(scales)
data(MU284) #アイスランドのデータ(税収、党の議席数など)
#####サンプリング
###ランダムサンプリング関数
rsmpl <- function(DATA, i) {
#i: 0 < i < 1
nsample <- round(nrow(DATA)*i)
p <<- rep(nsample/nrow(DATA), nrow(DATA))
s <<- srswor(nsample, nrow(DATA))
train <<- DATA[s==1, ]
test <<- DATA[s==0, ]
}
####バランスサンプリング関数
csmpl <- function(X, DATA, i) {
#i: 0 < i < 1
nsample <- round(nrow(DATA)*i)
p <<- rep(nsample/nrow(DATA), nrow(DATA))
s <<- samplecube(X, p, 1, FALSE)
train <<- DATA[s==1, ]
test <<- DATA[s==0, ]
}
#csmpl(X, smpl, 0.01)
###サンプルと母集団の統計量比較
stat_comp <- function(sample, comp) {
#出力したい変数に限定していると仮定
rbind(summary(sample)[4, ], summary(comp)[4, ])
}
#stat_comp(train, smpl)
###Horvitz-Thompson 推定量
HT_comp <- function(sample, comp, pik, s) {
HT <- HTestimator(sample, pik[s==1])
CP <- sum(comp)
RMSE <- sqrt((HT-CP)^2)
R <<- data.frame(HT=HT, COMP=CP, RMSE=RMSE)
}
#HT_comp(train$age, smpl$age, p ,s)
####main()
###Test of Random Sampling
n <- c(0.01, 0.05, 0.1, 0.2, 0.3, 0.4, 0.5)
RSLT1 <- data.frame(HT=NULL, COMP=NULL, RMSE=NULL)
for(i in 1:length(n)) {
rsmpl(MU284, n[i])
HT_comp(train$RMT85, MU284$RMT85, p, s)
RSLT1 <- rbind(RSLT1, R)
}
TMP <- data.frame(Smpl=rep(281,7)*n, Pop=rep(281,7), PCNT=n)
RSLT1 <- cbind(TMP, RSLT1)
###Test of Balanced Sampling
n <- c(0.01, 0.05, 0.1, 0.2, 0.3, 0.4, 0.5)
RSLT2 <- data.frame(HT=NULL, COMP=NULL, RMSE=NULL)
X <-cbind(MU284$P75,MU284$CS82,MU284$SS82,MU284$S82,MU284$ME84,MU284$REV84)
for(i in 1:length(n)) {
csmpl(X, MU284, n[i])
HT_comp(train$RMT85, MU284$RMT85, p, s)
RSLT2 <- rbind(RSLT2, R)
}
TMP <- data.frame(Smpl=rep(281,7)*n, Pop=rep(281,7), PCNT=n)
RSLT2 <- cbind(TMP, RSLT2)
####可視化
RSLT1$CLASS <- "02Random"
RSLT2$CLASS <- "01Balanced"
RSLT <- rbind(RSLT1, RSLT2)
RSLT$CLASS <- as.factor(RSLT$CLASS)
gg <- ggplot(RSLT, aes(x=PCNT, y=RMSE, colour=CLASS)) + geom_line()
gg <- gg + xlab("Percent(sample/Polulation)") +
scale_x_continuous(labels = percent)
gg
####Box-plotで分布を比較
###Test of Random Sampling
n <- c(0.01, 0.05, 0.1, 0.2, 0.3, 0.4, 0.5)
RAND <- NULL
for(i in 1:length(n)) {
rsmpl(MU284, n[i])
tmp <- data.frame(n=rep(n[i], nrow(train)),
RMT85=train$RMT85,
class=rep(paste0("N=",n[i]), nrow(train)))
RAND <- rbind(RAND, tmp)
}
tmp <- data.frame(n=rep(1.00, nrow(MU284)),
RMT85=MU284$RMT85,
class=rep("N=1.00", nrow(MU284)))
RAND <- rbind(RAND, tmp)
###Test of Balanced Sampling
n <- c(0.01, 0.05, 0.1, 0.2, 0.3, 0.4, 0.5)
BLNC <- NULL
X <-cbind(MU284$P75,MU284$CS82,MU284$SS82,MU284$S82,MU284$ME84,MU284$REV84)
for(i in 1:length(n)) {
csmpl(X, MU284, n[i])
tmp <- data.frame(n=rep(n[i], nrow(train)),
RMT85=train$RMT85,
class=rep(paste0("N=",n[i]), nrow(train)))
BLNC <- rbind(BLNC, tmp)
}
tmp <- data.frame(n=rep(1.00, nrow(MU284)),
RMT85=MU284$RMT85,
class=rep("N=1.00", nrow(MU284)))
BLNC <- rbind(BLNC, tmp)
###Control
n <- c(0.01, 0.05, 0.1, 0.2, 0.3, 0.4, 0.5)
CNTR <- NULL
for(i in 1:length(n)) {
tmp <- data.frame(n=rep(n[i], nrow(MU284)),
RMT85=MU284$RMT85,
class=rep(paste0("N=",n[i]), nrow(MU284)))
CNTR <- rbind(CNTR, tmp)
}
tmp <- data.frame(n=rep(1.00, nrow(MU284)),
RMT85=MU284$RMT85,
class=rep("N=1.00", nrow(MU284)))
CNTR <- rbind(CNTR, tmp)
####可視化
###データ加工
RAND$TYPE <- "02Random"
BLNC$TYPE <- "01Balanced"
CNTR$TYPE <- "03Control"
BOXP <- rbind(RAND, BLNC)
BOXP <- rbind(BOXP, CNTR)
BOXP$class <- as.factor(BOXP$class)
BOXP$TYPE <- as.factor(BOXP$TYPE)
gg <- ggplot(BOXP, aes(class, RMT85)) +
geom_boxplot(aes(fill = TYPE)) +
ylim(0, 300) + ggtitle("RMT85 of MU284") +
xlab("Ratio(sample/Polulation)")
gg
■参考文献
・概説 標本調査法 (統計ライブラリー)
- 作者: 土屋 隆裕
- 出版社/メーカー: 朝倉書店
- 発売日: 2009/08
- メディア: 単行本
cube法について書かれている和書はなさそうですが、標本調査の基礎にいてはこの本がわりと分かりやすいです。
・Sampling Algorithms (Springer Series in Statistics)
Sampling Algorithms (Springer Series in Statistics)
- 作者: Yves Tillé
- 出版社/メーカー: Springer
- 発売日: 2010/11/19
- メディア: ペーパーバック
cube法について詳しく書いてあるのはこの本みたいです。本当にちゃんとやろうとすると洋書になっちゃうんですよね。やっぱり学者の層が薄いのでしょうか。いずれ読まなきゃなこの本。
データサイエンティストの教養(ビジネス編)-データサイエンティストを目指して(2)- [データサイエンティスト]
今日はデータサイエンティストがビジネスを推進する上で有効な知識が得られる書籍を紹介することにします。以前の記事が比較的好評だったので続編を書いてみることにしました。物語でデータ分析の効果を理解できる本を集めてみました。いずれの本も難しい数式は登場せず、わくわくしながら読み進めることができます。
■分析力を駆使する企業 発展の五段階

世間ではデータサイエンティストの定義についてあまたの議論がありますが、このような人材を活用するための「組織」について言及している文書は数少ない印象です。本書ではアナリスト(=データサイエンティスト)の分類を試みた上で彼らのモチベーションを如何に維持すべきかとかリーダーシップとはどうあるべきか、又は組織設計はどうあればいいのかなどという経営課題について述べられている点が興味深いです。データサイエンティスト自身だけでなく、これからデータ分析を活用しようとしている経営幹部にもオススメの一冊です。
■儲からない時代に利益を生み出すRM(収益管理)のすべて
のすべて")
ちょっと古い本ですが、データ分析の威力を理解する上で貴重な本です。
上記で紹介した「分析力を駆使する企業」でイールドマネジメントやレベニューマネジメント(RM)というキーワードが登場するのですが、RMについて書かれた数少ない啓蒙書がこの本になります(1998年出版)。RMとは米国の航空業界を発祥とした予測技術と最適化技術を組み合わせて収益を最大化するアプローチです。日本でも航空・ホテル業界ではRMが浸透していますが、日本語の専門書が存在しないという状況です。RMは価格最適化(Pricing Optization)を包含する概念であり、今後は日本でもWebや金融業界に広まる可能性があると思っています。
本書では米国の航空業界でデータ分析を武器として活用した企業が如何に躍進したかということが物語として描かれており、わくわくしながらページをめくることができます。和書は絶版(新装希望)なので、図書館で入手するか、又は洋書"Revenue Management "を手に取る必要があります。
"を手に取る必要があります。
ちなみに本書の翻訳者は当時の三菱総研の研究員ですが、三菱総研は最近になってRMソリューショングループなる組織を作ってRMを推進しようとしているようです。さて、日本でもRMは流行るのでしょうか。
■その数学が戦略を決める (文春文庫)
")
定番で前回も紹介したのですが、やっぱりこの本が面白いです。回帰分析によるワインの価格予測などビジネスでデータ分析がどのように生かされているかということが躍動感のある文体で表現されています。著者のイアン・エアーズは最近になって「ヤル気の科学 行動経済学が教える成功の秘訣 」という本を出版したようです。私は未読ですが、こちらも面白そうですね。
」という本を出版したようです。私は未読ですが、こちらも面白そうですね。
余談ですが、翻訳者の山形浩生は評論家としても結構有名で浅田彰にケチをつけて論争になったことがありました。そんな人がなぜこの本を翻訳したのかと思ったら、SFとか前衛文学の翻訳をたくさんやっているということで、なんとなく納得したのでした。
■分析力を駆使する企業 発展の五段階
- 作者: トーマス・H・ダベンポート
- 出版社/メーカー: 日経BP社
- 発売日: 2011/05/26
- メディア: 単行本
世間ではデータサイエンティストの定義についてあまたの議論がありますが、このような人材を活用するための「組織」について言及している文書は数少ない印象です。本書ではアナリスト(=データサイエンティスト)の分類を試みた上で彼らのモチベーションを如何に維持すべきかとかリーダーシップとはどうあるべきか、又は組織設計はどうあればいいのかなどという経営課題について述べられている点が興味深いです。データサイエンティスト自身だけでなく、これからデータ分析を活用しようとしている経営幹部にもオススメの一冊です。
■儲からない時代に利益を生み出すRM(収益管理)のすべて
- 作者: ロバート・G. クロス
- 出版社/メーカー: 日本実業出版社
- 発売日: 1998/10
- メディア: 単行本
ちょっと古い本ですが、データ分析の威力を理解する上で貴重な本です。
上記で紹介した「分析力を駆使する企業」でイールドマネジメントやレベニューマネジメント(RM)というキーワードが登場するのですが、RMについて書かれた数少ない啓蒙書がこの本になります(1998年出版)。RMとは米国の航空業界を発祥とした予測技術と最適化技術を組み合わせて収益を最大化するアプローチです。日本でも航空・ホテル業界ではRMが浸透していますが、日本語の専門書が存在しないという状況です。RMは価格最適化(Pricing Optization)を包含する概念であり、今後は日本でもWebや金融業界に広まる可能性があると思っています。
本書では米国の航空業界でデータ分析を武器として活用した企業が如何に躍進したかということが物語として描かれており、わくわくしながらページをめくることができます。和書は絶版(新装希望)なので、図書館で入手するか、又は洋書"Revenue Management
ちなみに本書の翻訳者は当時の三菱総研の研究員ですが、三菱総研は最近になってRMソリューショングループなる組織を作ってRMを推進しようとしているようです。さて、日本でもRMは流行るのでしょうか。
■その数学が戦略を決める (文春文庫)
- 作者: イアン エアーズ
- 出版社/メーカー: 文藝春秋
- 発売日: 2010/06/10
- メディア: 文庫
定番で前回も紹介したのですが、やっぱりこの本が面白いです。回帰分析によるワインの価格予測などビジネスでデータ分析がどのように生かされているかということが躍動感のある文体で表現されています。著者のイアン・エアーズは最近になって「ヤル気の科学 行動経済学が教える成功の秘訣
余談ですが、翻訳者の山形浩生は評論家としても結構有名で浅田彰にケチをつけて論争になったことがありました。そんな人がなぜこの本を翻訳したのかと思ったら、SFとか前衛文学の翻訳をたくさんやっているということで、なんとなく納得したのでした。
ROC曲線をggplot2で描画 [R]
ROC曲線をRの美麗な可視化パッケージであるggplot2で表示するプログラムを作ってみました。
ROCを描画するパッケージとしてEpiというものがあるのだが、ちょっと出力される画像が好みではないのでggplot2でやってみました。三重大学の奥村先生のサイトを参考にしました。
【実行結果】
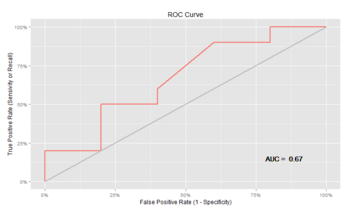
やっぱりggplot2はキレイでいいですね!
◆参考文献
・マシンラーニング (Rで学ぶデータサイエンス 6)
")
ROCやAUCの基本的な考え方はこの本の1章にあります。
ROCを描画するパッケージとしてEpiというものがあるのだが、ちょっと出力される画像が好みではないのでggplot2でやってみました。三重大学の奥村先生のサイトを参考にしました。
ROC <- function(score, actual) {
###ROC-AUC計算
o = order(score, decreasing = T)
fp = tp = fp_prev = tp_prev = 0
nF = sum(actual == F)
nT = sum(actual == T)
score_prev = -Inf
ber_min = Inf
area = 0
rx = ry = numeric(length(o))
n = 0
#cat("i", "\t", "n", "\t", "score[j]", "\t", "tp", "\t", "fp", "\t", "rx[n]", "\t", "ry[n]", "\t", "area", "\t", "AUC", "\n")
for (i in seq_along(o)) {
j = o[i]
if (score[j] != score_prev) {
area = area + (fp - fp_prev) * (tp + tp_prev) / 2
n = n + 1
rx[n] = fp/nF
ry[n] = tp/nT
ber = (fp/nF + 1 - tp/nT)/2
AUC = area/(nF*nT)
#cat(i, "\t", n, "\t", score[j], "\t", tp, "\t", fp, "\t", rx[n], "\t", ry[n], "\t", area, "\t", AUC, "\n")
if (ber < ber_min) {
ber_min = ber
th = score_prev
rx_best = fp/nF
ry_best = tp/nT
}
score_prev = score[j]
fp_prev = fp
tp_prev = tp
}
if (actual[j] == T) {
tp = tp + 1
} else {
fp = fp + 1
}
}
area = area + (fp - fp_prev) * (tp + tp_prev) / 2
AUC = area/(nF*nT)
n = n + 1
rx[n] = fp/nF # = 1
ry[n] = tp/nT # = 1
###ggplot2で可視化
AUC <- round(AUC, digits = 4)
tmp <- data.frame(x=rx, y=ry)
label <- paste("AUC = ", AUC)
gg <- ggplot(tmp) + geom_path(aes(x,y, color = "red"), size = 1.0) +
geom_path(data=data.frame(x = c(0,1), y = c(0,1)),aes(x,y), colour = "gray", size = 1.0) +
scale_x_continuous("False_Positive Rate (1 - Specificity)", labels=percent, limits = c(0, 1)) +
scale_y_continuous("True_Positive Rate (Sensivity or Recall)", labels=percent,limits = c(0, 1)) +
theme(legend.position = "none") +
ggtitle("ROC Curve") +
geom_text(data = NULL, x = 0.85, y = 0.15, label = label, colour = "black")
print(gg)
###ROC-AUC計算
cat("\n")
cat("AUC =", area/(nF*nT), "th =", th, "\n")
cat("BER =", (rx_best + (1-ry_best))/2,
"OR =", (ry_best/(1-ry_best))/(rx_best/(1-rx_best)), "\n")
print(table(score >= th, actual, dnn=c("Predicted","Actual")))
}
####実行例
library(ggplot2)
library(scales) #ggplot2のscaleを%表示にするのに必要
s = c(16,15,14,13,12,11,10, 9, 8, 8, 8, 8, 7, 6, 5) #score
a = c( T, T, F, T, T, T, F, T, T, T, T, F, F, T, F) #actual
ROC(s, a)
【実行結果】
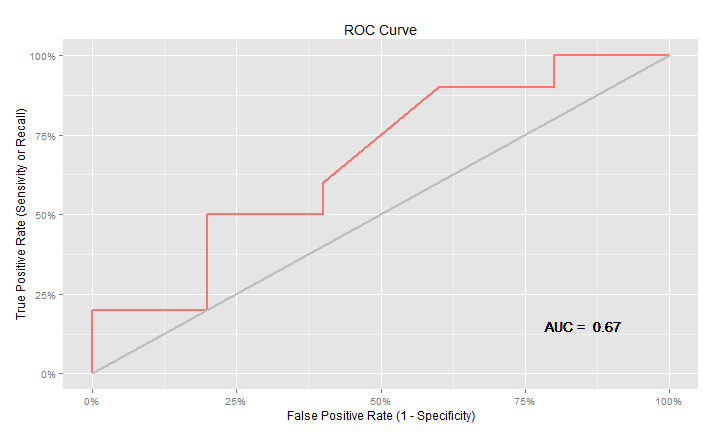
やっぱりggplot2はキレイでいいですね!
◆参考文献
・マシンラーニング (Rで学ぶデータサイエンス 6)
- 作者: 辻谷 将明
- 出版社/メーカー: 共立出版
- 発売日: 2009/06/09
- メディア: 単行本
ROCやAUCの基本的な考え方はこの本の1章にあります。
勇気を出して初めてのデータ分析 - データサイエンティストを目指して(1) - [データサイエンティスト]
今日は社会人がデータ分析をどのように独学で身に着けていけばいいかということを考えます。
ビッグデータがバズワードとなって以来、花形の学問のひとつとなったのが「統計学」です。統計学が重要なのは今も昔も変わらないわけですが、かつてはデータの分析になんて興味がなかった会社や部門がデータ分析を業務に役立てようとした結果、需要が増しています。
さて、私は社会人になってから統計学の素晴らしさを体感して勉強を始めました。筑波大学のビジネススクール(GSSM)で椿広計先生という大家の講義を受けて開眼しました。そういう意味では実に幸運だったと思います。
スクールに通って統計学を身に着けるというのも一つの手なのでしょうが、万人がスクーリングできるわけではありません。独学で身に着けて行かないといけない人が大半ではないでしょうか。大丈夫です。独学でも統計学を使いこなせるようになります。「数学」なんて・・・。という文系の人も躊躇する必要はありません。データ分析は車の運転と同じで、慣れると自然にやれてしまうもんです。
さて、もったいぶってもしょうがないので本論に入りましょう。データ分析をスムーズに身に着けるコツは「初めに理論を学ばないことです」。つまり、最初に「統計学」を勉強するとダメなのです。
どういうことでしょうか?大学の講義で使われる統計学の教科書は伝統な確率論から入り、平均・分散などの統計量の説明、そして仮説検定という推測統計学を経てようやく実務でもよく使われる回帰分析に到達します。それまで数式のオンパレードという教科書も少なくありません。今でこそ「マンガでわかる統計学 」みたいなイメージが掴める入門書がありますが、このような入門書でも実データを分析しようとするとどうやって使いこなしていいか分からなくなるのです。
」みたいなイメージが掴める入門書がありますが、このような入門書でも実データを分析しようとするとどうやって使いこなしていいか分からなくなるのです。
社会人は身近なデータをいじってみることから始めることが重要です。実践からスタートするのです。RやSPSSなどの専門のツールを曲がりなりにもいじってみる。回帰分析をやってみることです。理論が分からなくても気にする必要はありません。データをツールにつっこんで分析機能(関数)を駆使して予測して精度を確認する。又はいろいろな方法で可視化してみて仮説を考えてみる。まずはコレです。理屈ぬきでやれることをやってみるのです。
ツールを使っているうちに統計的分析で出来ることが体感できてきます。どのようにデータを使えば予測が上手くいくのかとかどのような変数が重要なのかということが分かってくるのです。これだけでも実務を回すことができるようになります。今のツールは優秀なのでなんとなく上手くいってしまうのです。
料理に例えて言うならば、素材や機材についてあれこれ知るよりも先ずははレシピを覚えてしまって、ほどほど上手い料理を作れるようになることが大切です。それなりに上手い料理を作ることができれば、人を喜ばせることができます。素材や機材などに凝るのは後回しでよろしいわけです。
さて、ここまでが初めの一歩。このレベルでは理論はとりあえず置いておいて、ツールに慣れ親しんでそれなりの結果を出せればそれでいいのです。では、それから先に進にはどうすればいいか。それは「基礎を知って合理的に応用できるようになること」です。
つまり、理屈を深く知る必要がありますので、世の中にごまんとある数式だらけの入門書を読み解きましょう。怖がる必要はありません。今までにデータ分析の経験を積んできたあなたならいくつもの発見があるはずです。経験的に知っていたことの舞台裏について好奇心を持って読み進めることができるでしょう。統計学を始めようとして手に取った数式だらけで無味乾燥だと思われた本の印象ががらりと変わるはずです。その美しい仕組みに惚れるようになることでしょう。このように感じられれば、あなたは次のステージに進んだということになります。
■初めに手元に置いておくべき本
・Rによるデータサイエンス - データ解析の基礎から最新手法まで

手法の宝庫です。データサイエンス(統計学+機械学習)という分野には多くの手法があります。視野を広げるために有用な本です。私は特許情報の分析から分析屋としてのキャリアをスタートしたのですが、統計的手法で何ができるのか?ということをこの本から学びました。
・ビジネスへの統計モデルアプローチ
")
恩師である椿先生の本です。財務諸表を材料に回帰分析の進め方が分かりやすく解説してあります。テキストにあるデータが入手できないところが難点ですが、統計モデルの使い方が理解できます。
・その数学が戦略を決める
データ分析を駆使してビジネスを成功に導いた事例が物語として解説されています。最初は理論よりもこのような物語を読む方がイメージしやすいと思います。
■初めに読もうとしてはいけない本
・統計学入門
")
理屈を知る上での入門書です。良書です。が、ある程度、データ分析を経験してからの方が吸収できます。買っておいて積読しておくのもいいでしょうが、未経験の社会人が最初に読み解こうとしてはいけない本です。
ビッグデータがバズワードとなって以来、花形の学問のひとつとなったのが「統計学」です。統計学が重要なのは今も昔も変わらないわけですが、かつてはデータの分析になんて興味がなかった会社や部門がデータ分析を業務に役立てようとした結果、需要が増しています。
さて、私は社会人になってから統計学の素晴らしさを体感して勉強を始めました。筑波大学のビジネススクール(GSSM)で椿広計先生という大家の講義を受けて開眼しました。そういう意味では実に幸運だったと思います。
スクールに通って統計学を身に着けるというのも一つの手なのでしょうが、万人がスクーリングできるわけではありません。独学で身に着けて行かないといけない人が大半ではないでしょうか。大丈夫です。独学でも統計学を使いこなせるようになります。「数学」なんて・・・。という文系の人も躊躇する必要はありません。データ分析は車の運転と同じで、慣れると自然にやれてしまうもんです。
さて、もったいぶってもしょうがないので本論に入りましょう。データ分析をスムーズに身に着けるコツは「初めに理論を学ばないことです」。つまり、最初に「統計学」を勉強するとダメなのです。
どういうことでしょうか?大学の講義で使われる統計学の教科書は伝統な確率論から入り、平均・分散などの統計量の説明、そして仮説検定という推測統計学を経てようやく実務でもよく使われる回帰分析に到達します。それまで数式のオンパレードという教科書も少なくありません。今でこそ「マンガでわかる統計学
社会人は身近なデータをいじってみることから始めることが重要です。実践からスタートするのです。RやSPSSなどの専門のツールを曲がりなりにもいじってみる。回帰分析をやってみることです。理論が分からなくても気にする必要はありません。データをツールにつっこんで分析機能(関数)を駆使して予測して精度を確認する。又はいろいろな方法で可視化してみて仮説を考えてみる。まずはコレです。理屈ぬきでやれることをやってみるのです。
ツールを使っているうちに統計的分析で出来ることが体感できてきます。どのようにデータを使えば予測が上手くいくのかとかどのような変数が重要なのかということが分かってくるのです。これだけでも実務を回すことができるようになります。今のツールは優秀なのでなんとなく上手くいってしまうのです。
料理に例えて言うならば、素材や機材についてあれこれ知るよりも先ずははレシピを覚えてしまって、ほどほど上手い料理を作れるようになることが大切です。それなりに上手い料理を作ることができれば、人を喜ばせることができます。素材や機材などに凝るのは後回しでよろしいわけです。
さて、ここまでが初めの一歩。このレベルでは理論はとりあえず置いておいて、ツールに慣れ親しんでそれなりの結果を出せればそれでいいのです。では、それから先に進にはどうすればいいか。それは「基礎を知って合理的に応用できるようになること」です。
つまり、理屈を深く知る必要がありますので、世の中にごまんとある数式だらけの入門書を読み解きましょう。怖がる必要はありません。今までにデータ分析の経験を積んできたあなたならいくつもの発見があるはずです。経験的に知っていたことの舞台裏について好奇心を持って読み進めることができるでしょう。統計学を始めようとして手に取った数式だらけで無味乾燥だと思われた本の印象ががらりと変わるはずです。その美しい仕組みに惚れるようになることでしょう。このように感じられれば、あなたは次のステージに進んだということになります。
■初めに手元に置いておくべき本
・Rによるデータサイエンス - データ解析の基礎から最新手法まで
Rによるデータサイエンス - データ解析の基礎から最新手法まで
- 作者: 金 明哲
- 出版社/メーカー: 森北出版
- 発売日: 2007/10/13
- メディア: 単行本(ソフトカバー)
手法の宝庫です。データサイエンス(統計学+機械学習)という分野には多くの手法があります。視野を広げるために有用な本です。私は特許情報の分析から分析屋としてのキャリアをスタートしたのですが、統計的手法で何ができるのか?ということをこの本から学びました。
・ビジネスへの統計モデルアプローチ
ビジネスへの統計モデルアプローチ (シリーズ〈ビジネスの数理〉)
- 作者: 椿 広計
- 出版社/メーカー: 朝倉書店
- 発売日: 2006/07/01
- メディア: 単行本(ソフトカバー)
恩師である椿先生の本です。財務諸表を材料に回帰分析の進め方が分かりやすく解説してあります。テキストにあるデータが入手できないところが難点ですが、統計モデルの使い方が理解できます。
・その数学が戦略を決める
- 作者: イアン エアーズ
- 出版社/メーカー: 文藝春秋
- 発売日: 2010/06/10
- メディア: 文庫
データ分析を駆使してビジネスを成功に導いた事例が物語として解説されています。最初は理論よりもこのような物語を読む方がイメージしやすいと思います。
■初めに読もうとしてはいけない本
・統計学入門
- 作者:
- 出版社/メーカー: 東京大学出版会
- 発売日: 1991/07/09
- メディア: 単行本
理屈を知る上での入門書です。良書です。が、ある程度、データ分析を経験してからの方が吸収できます。買っておいて積読しておくのもいいでしょうが、未経験の社会人が最初に読み解こうとしてはいけない本です。
ビッグデータ時代のマーケティング―ベイジアンモデリングの活用 [ビッグデータ]
")
ビッグデータ時代のマーケティング―ベイジアンモデリングの活用 (KS社会科学専門書)
- 作者: 佐藤 忠彦
- 出版社/メーカー: 講談社
- 発売日: 2013/01/22
- メディア: 単行本(ソフトカバー)
新たにビッグデータ関係の本が出版されました。
その名も「ビッグデータ時代のマーケティング」
ちょっとあまりにも今の時代を意識し過ぎていないか!?というタイトルですが、内容は極めて硬派です。それもそのはず著者の佐藤博士は筑波大学ビジネス科学研究科(GSSM)の先生で、共著者である統計数理研究所所長の樋口先生と前所長の北川源四郎先生のお弟子さんであられます。つまり、日本の正統なベイジアンでいらっしゃるわけです。
そういうわけで、状態空間モデルをPOSデータに適用して"One to One"マーケティングを高度化するという佐藤先生の研究業績がビジネス向けの文体で分かりやすく書かれています。ビッグデータの時代でも顧客毎にパラメータを推定しようとするとデータ不足となり、これを解決するにはベイズ的なアプローチがどうしても必要になるという今日的なトピックが扱われており非常に参考になります。
階層ベイズなどの手法についても図を多用して解説されており、入門者の理解を助ける工夫が随所に見られ好感を持ちました。パラメータとデータの関係をグラフィカルに記述するDAG(Directed Acyclic Graph)というものがあると知り勉強になりました。企画のためか、数式は最小限となっており、また、Rなどのプログラミングコードなどは出てこないので、これらは他書で補う必要がありますが(本書の最後にある参考文献がとても有用です)、ビッグデータ時代の硬派な数理マーケティングの方向性を理解できる良書だと思いました。
POSデータの分析本は他にもありますが、最新のベイジアン時系列分析にフォーカスしているマーケティングの和書はこれが初めてでしょう。買いの一冊です。
■参考文献
・データ解析のための統計モデリング入門
")
データ解析のための統計モデリング入門――一般化線形モデル・階層ベイズモデル・MCMC (確率と情報の科学)
- 作者: 久保 拓弥
- 出版社/メーカー: 岩波書店
- 発売日: 2012/05/19
- メディア: 単行本
この本もベイズ的なデータ解析を非常に分かりやすく解説しています。WinBugsとRのコードがあるのが嬉しいです。マーケティングと生態学はちょっと似ていると思いました。
・ベイズ統計データ解析 (Rで学ぶデータサイエンス 3)
")
- 作者: 姜 興起
- 出版社/メーカー: 共立出版
- 発売日: 2010/07/24
- メディア: 単行本
・こちらの本はカルマンフィルターなどの時系列解析の理論とRコードが詳述されています。初級~中級者の役に立つ内容となっています。
パテントマップ3.0-特許情報の高度な活用に向けて- [知財]
パテントマップが急速に普及したのは21世紀になってからだと思われる。IT技術の革新によるデータストレージの大規模化やコモディティ化、更には機械学習技術の普及が要因として挙げられる。NRIやCAS(STN)がテキストマイニングツールを矢継ぎ早にリリースして、パテントマップは流行した。
このような工学的な技術だけでなくMBA的な経営技術の一般企業への浸透もこれを後押しした。戦略コンサルティング会社で使われているようなフレームワークを解説する本が書店に所狭しと並ぶようになり、別に海外のMBAコースに行かなくても経営学の枠組みを学べるようになった。パテントマップを知財戦略のみならず事業・全社戦略にも生かそうという機運が盛り上がったわけである。
さて、このような状況の中で立て続けにパテントマップがらみの本が出版されたので、工学・経営学的な視点から主要な本をレビューしてみたい。ちょっと前にWeb2.0というバズワードがあったが、それをまねてパテントマップx.0として、各々の世代的な特徴を整理する。
◆パテントマップ1.0
【特許調査とパテントマップ作成の実務】

パテントマップ1.0では、工学的には単純集計の可視化レベル。経営学的にはフレームワーク等の解釈系の技術が存在しない状態と定義する。ただし、この段階でも目的がはっきりしていれば十分に役に立つ。これから進出しようとしている分野の競合や技術の動向を俯瞰するのに有効である。上記の本は2011年に出版された比較的新しい本だ。バブルチャートなどのパテントマップの代表選手のつくり方がとても分かりやすくまとまっている。
ただ、この著者はExcel VBAを使ってマップ作成を自動化すると便利と書いているが、VBAのコード例までは書いていない。むしろ、サーチャーやインフォプロは少しでもプログラミング技術を習得すべきと私は思っているので、そのあたりについて書いた続編に期待したいところである。
◆パテントマップ2.0
【特許情報分析とパテントマップ作成入門】

この段階では、工学的には上記と同じ単純集計レベル。経営学的にはフレームワークを積極的に活用してパテントマップから施策に結びつく知見を見出そうとするものである。上記の本については以前にレビューしたので詳細はそちらに譲るが、この本ではマイケル・ポーター流のフレームワークを知財担当者に紹介するというユニークな試みがあるのに、それを用いたケーススタディが不十分なところが残念。続編(ケーススタディ集)に期待したい。
◆パテントマップ3.0
【特許情報のテキストマイニング―技術経営のパラダイム転換】

最終形態。工学的には高度な数理テクニックを駆使、その結果を経営学の枠組みを用いて解釈することで戦略立案に生かすというのがパテントマップ3.0。ここまでくると定性的にも定量的にも高度な分析が行われることになる。ビッグデータを扱う(コンサル型の)データサイエンティストの仕事に近くなる。
上記の本では数理システム社のTextMiningStudioやオープンソースのRという分析ツールを使って特許文書を技術経営の視点で分析しようという意欲作。単にツールに突っ込んでみるようなやっつけではなく、数式も書かれており非負値行列因子分解(NMF)といった比較的新しいメソッドを用いて分析しているところが面白い。
しかし、本書はケーススタディとしては役に立つと思うが、分析ツールのチュートリアルが十分ではないのでこれらの知識は他で補う必要があるだろう。テキストマイニングの入門については以前の記事を参考までに挙げておく。
-----
パテントマップから有効な知識を獲得するためには、経営・数理・ITの技術をバランスよく活用することが重要だと思う。もちろん、一人でやることが難しいなら、異なる得意分野をもった人材のチームで問題解決にあたるとよいだろう。
(まぁ、しかし、単純集計でも解釈系がしっかりしていれば十分強力な分析ができるので、どんな分析をやるにせよ目的意識をしっかりもって多面的に分析するのが一番大事だと思う。数理技術が高度でも施策に結びつかなければ何の意味もない。)
このような工学的な技術だけでなくMBA的な経営技術の一般企業への浸透もこれを後押しした。戦略コンサルティング会社で使われているようなフレームワークを解説する本が書店に所狭しと並ぶようになり、別に海外のMBAコースに行かなくても経営学の枠組みを学べるようになった。パテントマップを知財戦略のみならず事業・全社戦略にも生かそうという機運が盛り上がったわけである。
さて、このような状況の中で立て続けにパテントマップがらみの本が出版されたので、工学・経営学的な視点から主要な本をレビューしてみたい。ちょっと前にWeb2.0というバズワードがあったが、それをまねてパテントマップx.0として、各々の世代的な特徴を整理する。
◆パテントマップ1.0
【特許調査とパテントマップ作成の実務】
- 作者: 東 智朗
- 出版社/メーカー: オーム社
- 発売日: 2011/11
- メディア: 単行本
パテントマップ1.0では、工学的には単純集計の可視化レベル。経営学的にはフレームワーク等の解釈系の技術が存在しない状態と定義する。ただし、この段階でも目的がはっきりしていれば十分に役に立つ。これから進出しようとしている分野の競合や技術の動向を俯瞰するのに有効である。上記の本は2011年に出版された比較的新しい本だ。バブルチャートなどのパテントマップの代表選手のつくり方がとても分かりやすくまとまっている。
ただ、この著者はExcel VBAを使ってマップ作成を自動化すると便利と書いているが、VBAのコード例までは書いていない。むしろ、サーチャーやインフォプロは少しでもプログラミング技術を習得すべきと私は思っているので、そのあたりについて書いた続編に期待したいところである。
◆パテントマップ2.0
【特許情報分析とパテントマップ作成入門】
- 作者: 野崎篤志
- 出版社/メーカー: 発明推進協会
- 発売日: 2011/12/09
- メディア: 単行本(ソフトカバー)
この段階では、工学的には上記と同じ単純集計レベル。経営学的にはフレームワークを積極的に活用してパテントマップから施策に結びつく知見を見出そうとするものである。上記の本については以前にレビューしたので詳細はそちらに譲るが、この本ではマイケル・ポーター流のフレームワークを知財担当者に紹介するというユニークな試みがあるのに、それを用いたケーススタディが不十分なところが残念。続編(ケーススタディ集)に期待したい。
◆パテントマップ3.0
【特許情報のテキストマイニング―技術経営のパラダイム転換】
- 作者: 豊田 裕貴
- 出版社/メーカー: ミネルヴァ書房
- 発売日: 2011/03/30
- メディア: 単行本
最終形態。工学的には高度な数理テクニックを駆使、その結果を経営学の枠組みを用いて解釈することで戦略立案に生かすというのがパテントマップ3.0。ここまでくると定性的にも定量的にも高度な分析が行われることになる。ビッグデータを扱う(コンサル型の)データサイエンティストの仕事に近くなる。
上記の本では数理システム社のTextMiningStudioやオープンソースのRという分析ツールを使って特許文書を技術経営の視点で分析しようという意欲作。単にツールに突っ込んでみるようなやっつけではなく、数式も書かれており非負値行列因子分解(NMF)といった比較的新しいメソッドを用いて分析しているところが面白い。
しかし、本書はケーススタディとしては役に立つと思うが、分析ツールのチュートリアルが十分ではないのでこれらの知識は他で補う必要があるだろう。テキストマイニングの入門については以前の記事を参考までに挙げておく。
-----
パテントマップから有効な知識を獲得するためには、経営・数理・ITの技術をバランスよく活用することが重要だと思う。もちろん、一人でやることが難しいなら、異なる得意分野をもった人材のチームで問題解決にあたるとよいだろう。
(まぁ、しかし、単純集計でも解釈系がしっかりしていれば十分強力な分析ができるので、どんな分析をやるにせよ目的意識をしっかりもって多面的に分析するのが一番大事だと思う。数理技術が高度でも施策に結びつかなければ何の意味もない。)
Pythonでデータ解析[Pandas] -その2- 重回帰① [データマイニング]

- 作者: Wes Mckinney
- 出版社/メーカー: Oreilly & Associates Inc
- 発売日: 2012/10/29
- メディア: ペーパーバック
Pythonのマイニングパッケージをいじってみています。
とりあえず、PandasやScikit-learnを使って重回帰をやってみる。Pandas部分については↑などを参考にしています。Scikit-learnについてはもっぱらGoogle先生だのみ。専門に書かれている本はないのかな?
◆先ずは環境設定
####環境設定
import os
import sys
import pandas as pd
from sklearn import linear_model
####ディレクトリ設定
os.chdir('C:/*******(ワーキングディレクトリ)*****')
◆データ読み込みと状況確認
prs = pd.read_csv('prostate.csv')
##↓データは以下を使用
##http://www-stat.stanford.edu/~tibs/ElemStatLearn/datasets/prostate.data
####データ状況確認
prs.info()
#
#Int64Index: 97 entries, 0 to 96
#Data columns:
#lcavol 97 non-null values
#lweight 97 non-null values
#age 97 non-null values
#lbph 97 non-null values
#svi 97 non-null values
#lcp 97 non-null values
#gleason 97 non-null values
#pgg45 97 non-null values
#lpsa 97 non-null values
#train 97 non-null values
#dtypes: float64(5), int64(4), object(1)
prs.describe()
#Out[1]:
# lcavol lweight age lbph svi lcp gleason \
#count 97.000000 97.000000 97.000000 97.000000 97.000000 97.000000 97.000000
#mean 1.350010 3.628943 63.865979 0.100356 0.216495 -0.179366 6.752577
#std 1.178625 0.428411 7.445117 1.450807 0.413995 1.398250 0.722134
#min -1.347074 2.374906 41.000000 -1.386294 0.000000 -1.386294 6.000000
#25% 0.512824 3.375880 60.000000 -1.386294 0.000000 -1.386294 6.000000
#50% 1.446919 3.623007 65.000000 0.300105 0.000000 -0.798508 7.000000
#75% 2.127041 3.876396 68.000000 1.558145 0.000000 1.178655 7.000000
#max 3.821004 4.780383 79.000000 2.326302 1.000000 2.904165 9.000000
#
# pgg45 lpsa
#count 97.000000 97.000000
#mean 24.381443 2.478387
#std 28.204035 1.154329
#min 0.000000 -0.430783
#25% 0.000000 1.731656
#50% 15.000000 2.591516
#75% 40.000000 3.056357
#max 100.000000 5.582932
★".describe()"でRのsummaryと類似出力
◆データ作成
###学習データ
train = prs[prs['train'] == 'T']
###テストデータ
test = prs[prs['train'] == 'F']
###学習データ準備
Y = train.pop('lpsa') #目的変数をセット
X = train.ix[:,:'pgg45'] #説明変数をセット
★列の選択がRとは異なる構文。どうやるのか分からずハマった。google先生に聞いてもそれらしいものを見つけるのに苦労した(^^;
★scikit-learnでは目的変数と説明変数を分けておく必要がある
◆いよいよモデリング
###通常の重回帰 prs_ols = linear_model.LinearRegression() prs_ols.fit(X, Y) #係数 prs_ols.coef_ #Out[1]: #array([ 0.57654319, 0.61402 , -0.01900102, 0.14484808, 0.73720864, # -0.20632423, -0.02950288, 0.00946516]) #切片 prs_ols.intercept_ #Out[1]: 0.42917013284910865 #列名を付与して表示 df1 = DataFrame(prs_ols.intercept_, index = ['(intercept)'], columns = ['Est Coeff-ols']) df2 = DataFrame(prs_ols.coef_, index = X, columns = ['Est Coeff-ols']) pd.concat([df1, df2]) # 縦結合(rbind) #Out[1]: # Est Coeff-ols # (intercept) 0.429170 #lcavol 0.564341 #lweight 0.622020 #age -0.021248 #lbph 0.096713 #svi 0.761673 #lcp -0.106051 #gleason 0.049228 #pgg45 0.004458
★RのようにP値や決定係数は出力されないのでしょうか。これだとちょっと使いにくい。Orangeパッケージの方がいいのかな。まだまだ勉強が足りないな~。
★RみたいなPredict関数はあるようだが、なんだかうまくいかなかった。これも宿題。
◆参考サイト
Python:リッジ回帰
http://blog.livedoor.jp/norikazu197768/archives/14995354.html
入門機械学習[O'Reilly]をさらっと読んでみた! [データマイニング]

- 作者: Drew Conway
- 出版社/メーカー: オライリージャパン
- 発売日: 2012/12/22
- メディア: 大型本
新しい機械学習の本がオライリーから出版された。
"Machine Learning for Hackers"という洋書の邦訳である。
内容は機械学習の代表的なアルゴリズムをRで実行して試そうというもの。邦題にあるように「入門」という文字が適しているように思われる。初学者はサンプルコードを実行することで各アルゴリズムの特徴を掴むことができるだろう。リッジ回帰などの正則化についても言及されており、最近のトレンドが盛り込まれている。
そして、可視化に美麗なggplot2を使っているところも特徴である。ggplot2では多様なビジュアル表現が可能であり、筆者もデータの理解や結果の解釈をする際に重宝している。ただ、本書は白黒なのでカラーでその表現の美しさを実感できないのが残念。いくつものWebサイトでggplot2について紹介されているので適宜参照しながら読み進めるのがよいだろう。
本書ではRコードは示されているが、関数の中身(アルゴリズムの仕組み)についてはあまり詳しく言及されていない。当然、数式もない。アルゴリズムのコードを学習したい場合には「集合知プログラミング」(参考図書①)が参考になる。同書にはPythonのサンプルコードが記述されている。また、数式を追いたい場合には「パターン認識と機械学習」(参考図書②)や"The Elements of Statistical Learning"(参考図書③)を読み進めるとより理解が深まるのではないだろうか。
ちなみに、私はコツコツと③でLASSOについて勉強しているところである・・・。③はLASSOの考案者である"Robert Tibshirani"が著者の1人であるため、リッジ回帰やLASSOなどの正則化がらみの勉強には最適ではないかと思っている。
◆参考図書
①集合知プログラミング

- 作者: Toby Segaran
- 出版社/メーカー: オライリージャパン
- 発売日: 2008/07/25
- メディア: 大型本
②パターン認識と機械学習

- 作者: C.M. ビショップ
- 出版社/メーカー: 丸善出版
- 発売日: 2012/04/05
- メディア: 単行本(ソフトカバー)
③The Elements of Statistical Learning
")
- 作者: Trevor Hastie
- 出版社/メーカー: Springer-Verlag
- 発売日: 2009/03
- メディア: ハードカバー
Hadoopの敷居が下がり始めた [ビッグデータ]
Hadoopは基本的にLinux上で動作することもあって初心者には難しいイメージがあったが、最近は入門的な書籍やWebサイトが増えてきたために敷居が下がってきたようである。よい傾向だ。
覚書程度だが↓などを見ておけば基本が身に付くと思われる。
【書籍】
■パターンでわかるHadoop MapReduce ビッグデータのデータ処理入門
・↓の書籍ではWindows+Cygwin+Eclipse+Pigでの環境構築手順から、実際のコードまで記述されておりなかなかよさそうである。オライリーに進む前の下地ができそう。
")
【Web】
■Hadoop入門
・IBMの入門資料がわかりやすい
http://www-06.ibm.com/jp/domino01/mkt/cnpages7.nsf/page/default-0041751B
■Hadoopでテキストマイニング
・このサイトはテキストマイニングに興味がある人が多いようなので参考のため↓をリンクした
「テキストマイニングで始めるHadoop活用」
http://www.atmarkit.co.jp/fjava/index/index_hadoop_tm.html
■NTTデータの実証実験
・膨大な分量の報告書 - Hadoopが一望できる
http://www.meti.go.jp/policy/mono_info_service/joho/downloadfiles/2010software_research/clou_dist_software.pdf
覚書程度だが↓などを見ておけば基本が身に付くと思われる。
【書籍】
■パターンでわかるHadoop MapReduce ビッグデータのデータ処理入門
・↓の書籍ではWindows+Cygwin+Eclipse+Pigでの環境構築手順から、実際のコードまで記述されておりなかなかよさそうである。オライリーに進む前の下地ができそう。
パターンでわかるHadoop MapReduce ビッグデータのデータ処理入門 (NEXT‐ONE)
- 作者: 三木 大知
- 出版社/メーカー: 翔泳社
- 発売日: 2012/08/28
- メディア: 大型本
【Web】
■Hadoop入門
・IBMの入門資料がわかりやすい
http://www-06.ibm.com/jp/domino01/mkt/cnpages7.nsf/page/default-0041751B
■Hadoopでテキストマイニング
・このサイトはテキストマイニングに興味がある人が多いようなので参考のため↓をリンクした
「テキストマイニングで始めるHadoop活用」
http://www.atmarkit.co.jp/fjava/index/index_hadoop_tm.html
■NTTデータの実証実験
・膨大な分量の報告書 - Hadoopが一望できる
http://www.meti.go.jp/policy/mono_info_service/joho/downloadfiles/2010software_research/clou_dist_software.pdf
SyntaxHighlighteの導入方法 [雑記]
このブログでもプログラミングコードを格好よく表示したかったので
"SyntaxHighlighter"を導入
■So-netブログでの導入法
①管理メニュー→デザイン→テンプレート管理→HTMLの追加
→コードコピペ(②)→適当な名前を付ける→新しいHTMLを適用
②次のタグの間に③のスクリプトをコピペ
<head>
ここにコピペ!
</head>
③スクリプト
【参考サイト】
・導入方法
http://kids-education.blog.so-net.ne.jp/2011-01-09
http://kamosan-android.blog.so-net.ne.jp/2011-05-03-2
http://blog.cartercole.com/2009/10/awesome-syntax-highlighting-made-easy.html
http://samidarehetima.blog9.fc2.com/blog-entry-85.html
・言語毎にハイライト
http://twp1016.blogspot.jp/
・行番号の設定
http://blog.serverkurabe.com/syntax-highlighter-setting
"SyntaxHighlighter"を導入
■So-netブログでの導入法
①管理メニュー→デザイン→テンプレート管理→HTMLの追加
→コードコピペ(②)→適当な名前を付ける→新しいHTMLを適用
②次のタグの間に③のスクリプトをコピペ
<head>
ここにコピペ!
</head>
③スクリプト
【参考サイト】
・導入方法
http://kids-education.blog.so-net.ne.jp/2011-01-09
http://kamosan-android.blog.so-net.ne.jp/2011-05-03-2
http://blog.cartercole.com/2009/10/awesome-syntax-highlighting-made-easy.html
http://samidarehetima.blog9.fc2.com/blog-entry-85.html
・言語毎にハイライト
http://twp1016.blogspot.jp/
・行番号の設定
http://blog.serverkurabe.com/syntax-highlighter-setting