パトリック・シルベストル さん




Pythonで状態空間モデリング(1) -時変の平均をもつ時系列モデルの状態空間表現(その1)- [統計学]
最近はPythonをデータ分析に活用する動きが活発になっている。Rとともに2大勢力になってきている。ついに「Pythonによるデータ分析入門 ―NumPy、pandasを使ったデータ処理 」という邦訳本も出版されたことだし、日本でもPythonをデータ分析に使う人が増えると思われる。予測モデルを作る際には一般的にはscikit-learnを使うわけだが、こちらは英語のリファレンスしかないので普及にはもう少し時間がかかるだろう。おそらく、scikit-learnについての日本語の解説書もそのうち出版されるのではないかと思っている。
」という邦訳本も出版されたことだし、日本でもPythonをデータ分析に使う人が増えると思われる。予測モデルを作る際には一般的にはscikit-learnを使うわけだが、こちらは英語のリファレンスしかないので普及にはもう少し時間がかかるだろう。おそらく、scikit-learnについての日本語の解説書もそのうち出版されるのではないかと思っている。
さて、私は状態空間モデリングの勉強を姜先生の「ベイズ統計データ解析 (Rで学ぶデータサイエンス 3) 」という本を使って進めている。この本はカルマンフィルタのRでの実装が記載されており、実に有用である。難しい数式が並ぶカルマンフィルタも実際のコードを解釈しながら勉強すると比較的シンプルで理解しやすことが分かった。
」という本を使って進めている。この本はカルマンフィルタのRでの実装が記載されており、実に有用である。難しい数式が並ぶカルマンフィルタも実際のコードを解釈しながら勉強すると比較的シンプルで理解しやすことが分かった。
さらに勉強を進めるべく本のRコードをPythonに翻訳してみた。このような翻訳作業によって状態空間モデリングとPythonの両方を一篇に身に着けてしまおうとある時に思いついた。これはなかなか学習効率がよいので今後も続けてみようと思う。やっぱり統計や機械学習の勉強はコーディングしてみるのが近道である。今回の記事では姜先生の本の7章を解説しつつRコードをPythonにへの翻訳を紹介する。
◆状態空間モデリング
・状態空間モデリングは時系列モデルの一種であり、非定常時系列をモデル化することができる。
・伝統的なARIMAモデルなどの時系列モデルを統一的に扱うことができる。
・カルマンフィルタなどの推定アルゴリズムが一見難しいのと分かりやすいRパッケージが少ないためか、あまり一般に普及していない気がする。姜先生の本はコードもあるし分かりやすいのでもっと読まれるべきであろう。
・状態空間モデルは次のようにシンプルな形をしている2つの式から構成される(状態空間表現と呼ばれている)。ところが、この式に複数の要素を導入でき複雑なモデルを構築することができる。シンプルさと複雑さが同居するところが面白いところだ。
・潜在変数を扱えるところもこのモデルの特徴。しかもモデラーの感覚を柔軟に式に導入することができる。これが最大の魅力と現時点では考えている。
【状態空間表現】
・システムモデル
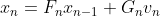
)
・観測モデル
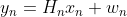
)
◆今回の事例:「時変の平均をもつ時系列モデルの状態空間表現」
・時変の平均をもつ時系列モデルを状態空間表現にしてみる
【時変の平均をもつ時系列モデル】
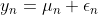
)
【潜在的な平均の推移】
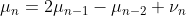
)
【状態空間表現】
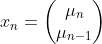 ,
,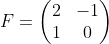 ,
,
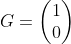 ,
,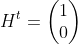 ,
,
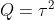 ,
, 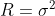
【Pythonコード】
(次回へ続く)

")
さて、私は状態空間モデリングの勉強を姜先生の「ベイズ統計データ解析 (Rで学ぶデータサイエンス 3)
さらに勉強を進めるべく本のRコードをPythonに翻訳してみた。このような翻訳作業によって状態空間モデリングとPythonの両方を一篇に身に着けてしまおうとある時に思いついた。これはなかなか学習効率がよいので今後も続けてみようと思う。やっぱり統計や機械学習の勉強はコーディングしてみるのが近道である。今回の記事では姜先生の本の7章を解説しつつRコードをPythonにへの翻訳を紹介する。
◆状態空間モデリング
・状態空間モデリングは時系列モデルの一種であり、非定常時系列をモデル化することができる。
・伝統的なARIMAモデルなどの時系列モデルを統一的に扱うことができる。
・カルマンフィルタなどの推定アルゴリズムが一見難しいのと分かりやすいRパッケージが少ないためか、あまり一般に普及していない気がする。姜先生の本はコードもあるし分かりやすいのでもっと読まれるべきであろう。
・状態空間モデルは次のようにシンプルな形をしている2つの式から構成される(状態空間表現と呼ばれている)。ところが、この式に複数の要素を導入でき複雑なモデルを構築することができる。シンプルさと複雑さが同居するところが面白いところだ。
・潜在変数を扱えるところもこのモデルの特徴。しかもモデラーの感覚を柔軟に式に導入することができる。これが最大の魅力と現時点では考えている。
【状態空間表現】
・システムモデル
・観測モデル
◆今回の事例:「時変の平均をもつ時系列モデルの状態空間表現」
・時変の平均をもつ時系列モデルを状態空間表現にしてみる
【時変の平均をもつ時系列モデル】
【潜在的な平均の推移】
【状態空間表現】
【Pythonコード】
#!/usr/bin/env python #-*- coding:utf-8 -*- ##package import numpy as np ##define Matrix L = 1; k = 2; m = 1 F = np.zeros((k, k)); G = np.zeros((k, m)) H = np.zeros((L, k)); R = np.identity(L) F[0][0] = 2; F[0][1] = -1; F[1][0] = 1 G[0][0] = 1; H[0][0] = 1
(次回へ続く)
Pythonによるデータ分析入門 ―NumPy、pandasを使ったデータ処理
- 作者: Wes McKinney
- 出版社/メーカー: オライリージャパン
- 発売日: 2013/12/26
- メディア: 大型本
- 作者: 姜 興起
- 出版社/メーカー: 共立出版
- 発売日: 2010/07/24
- メディア: 単行本
最小二乗法からp値まで [統計学]
線形回帰の基本は最小二乗法を実行して決定係数やp値を確認しながらモデルをブラッシュアップしていくことです。
Rにはlm関数などの便利なものがあるので内部ロジックがどうなっているのか、この関数を使っている限りは気になりません。しかし、いざ人に説明しようとすると内部ロジックに精通する必要が出てきます。というわけで、今日は最小二乗法かp値算出までの線形回帰の基本を確認したいと思います。結構、このあたりをきちんと理解していると次のステップに進みやすいでしょう。
■データ
・今回は次のデータを使います。
■最小二乗法によるパラメータの推定
・線形回帰の場合には最小二乗法=最尤法で次のシンプルな式を解くだけでパラメータを求めることができます。
^{-1}Xy)
・カンタンカンタン!
■決定係数
・修正済み決定係数: γ^2
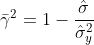
^2)
^2)
■t値
・βの仮説検定を行うにはt値を算出しておく必要があります。
^2}})

■p値
・最後に上記で求めた値からt分布を使ってp値を求めます。
■参考文献

・宮川先生のこの本では線形回帰がとても分かりやすく書かれています。上記のコーディングもこの本を参考にしました。おススメの一冊です。初学者には下記の本よりも分かりやすいことでしょう。(入門書としては下記が紹介されることが多いですが、こちらの方が記載が優しいので下記本に挫折した人でもこちらでリカバリーできる可能性があります。)
")
・この本も分かりやすいですが、入門書を数冊読んだ後の方がよいですね。宮川先生の本を先に一読されることをおススメします。
■全コード
Rにはlm関数などの便利なものがあるので内部ロジックがどうなっているのか、この関数を使っている限りは気になりません。しかし、いざ人に説明しようとすると内部ロジックに精通する必要が出てきます。というわけで、今日は最小二乗法かp値算出までの線形回帰の基本を確認したいと思います。結構、このあたりをきちんと理解していると次のステップに進みやすいでしょう。
■データ
・今回は次のデータを使います。
x <- c(45,33,39,40,42,30,53,45,42,31) #説明変数 y <- c(41,29,36,36,40,26,46,33,35,28) #目的変数 X <- matrix(1,10,2) #行列作成 X[,2] <- x #1列目 = 切片, 2列目=説明変数
■最小二乗法によるパラメータの推定
・線形回帰の場合には最小二乗法=最尤法で次のシンプルな式を解くだけでパラメータを求めることができます。
B <- t(X) %*% X; c <- t(X) %*% y; beta <- solve(B, c) a <- beta[1,]; b <- beta[2,] yhat <- a + b*x
・カンタンカンタン!
■決定係数
・修正済み決定係数: γ^2
#試行錯誤そのままなのでコードが冗長 n <- length(x) sy2 <- sum((y-mean(y))^2)/n sy <- sqrt(sy2) syx2 <- sum((y-a-b*x)^2)/n syx <- sqrt(syx2) sig2 <- n*syx2/(n-2) sig <- sqrt(sig2) sigy2 <- n*sy2/(n-1) rbar2 <- 1 - (sig2/sigy2)
■t値
・βの仮説検定を行うにはt値を算出しておく必要があります。
sx2 <- sum((x-mean(x))^2)/n sx <- sqrt(sx2) siga2 <- sig2 * sum(x^2) /(n^2*sx2) siga <- sqrt(siga2) sigb2 <- sig2/(n*sx2) sigb <- sqrt(sigb2) ta <- a / siga tb <- b / sigb
■p値
・最後に上記で求めた値からt分布を使ってp値を求めます。
pa <- (1 - pt(ta, n-2))*2 pb <- (1 - pt(tb, n-2))*2
■参考文献
- 作者: 宮川 公男
- 出版社/メーカー: 有斐閣
- 発売日: 1999/03
- メディア: 単行本
・宮川先生のこの本では線形回帰がとても分かりやすく書かれています。上記のコーディングもこの本を参考にしました。おススメの一冊です。初学者には下記の本よりも分かりやすいことでしょう。(入門書としては下記が紹介されることが多いですが、こちらの方が記載が優しいので下記本に挫折した人でもこちらでリカバリーできる可能性があります。)
- 作者:
- 出版社/メーカー: 東京大学出版会
- 発売日: 1991/07/09
- メディア: 単行本
・この本も分かりやすいですが、入門書を数冊読んだ後の方がよいですね。宮川先生の本を先に一読されることをおススメします。
■全コード
####DATA
x <- c(45,33,39,40,42,30,53,45,42,31) #説明変数
y <- c(41,29,36,36,40,26,46,33,35,28) #目的変数
X <- matrix(1,10,2) #行列作成
X[,2] <- x #1列目 = 切片, 2列目=説明変数
####Estimation
B <- t(X) %*% X; c <- t(X) %*% y; beta <- solve(B, c)
a <- beta[1,]; b <- beta[2,]
yhat <- a + b*x
####R-squared
n <- length(x)
sy2 <- sum((y-mean(y))^2)/n
sy <- sqrt(sy2)
syx2 <- sum((y-a-b*x)^2)/n
syx <- sqrt(syx2)
sig2 <- n*syx2/(n-2)
sig <- sqrt(sig2)
sigy2 <- n*sy2/(n-1)
rbar2 <- 1 - (sig2/sigy2)
rbar <- a / (sig*sqrt(n)*1)
####t-value
sx2 <- sum((x-mean(x))^2)/n
sx <- sqrt(sx2)
siga2 <- sig2 * sum(x^2) /(n^2*sx2)
siga <- sqrt(siga2)
sigb2 <- sig2/(n*sx2)
sigb <- sqrt(sigb2)
ta <- a / siga
tb <- b / sigb
####p-value
pa <- (1 - pt(ta, n-2))*2
pb <- (1 - pt(tb, n-2))*2
####Print
print(paste("a=", a))
print(paste("b=", b))
print(paste("rbar2=", rbar2))
print(paste("ta=", ta))
print(paste("tb=", tb))
print(paste("pa=", pa))
print(paste("pb=", pb))
ベイズ統計学入門 [統計学]
■ベイズ統計学を学ぶには
日本でもベイズ統計学に関する本が増えてきました。RやWinBUGSの普及ともにベイズが身近な存在になってきています。しかし、入門書などでは「主観確率」を扱えてビジネスに有用とか書いてありますが、なかなか一般企業でビジネスに使われている状況にはなっていないのではないかと思っています。
その理由はベイズモデルの複雑さ(柔軟さ)にあるのではないかと思います。たとえば、普通のロジットモデルに慣れてしまうと、階層ベイズを使ったロジットモデルを理解するのにちょっとしたハードルがあるように感じられます(少なくとも私はそうでした)。WinBUGSというMCMCサンプラーでモデリングするんだ~というところはなんとなく分かるんですが、モデル式をどのように記述すればいいのかイマイチ想像がつかないのです。
これから紹介する本のようにこのあたりの学習のしづらさを補うものが登場してきましたが、まだまだ入門~中級あたりをサポートする書籍が少ないのが現状のようです。様々なBUGSモデルとRコードを併記したベイズモデルの事例集があると便利と思うのですが、どこかの出版社で企画してくれないかな・・・。
そんなんなこんなで、以下、ベイズ上達のために有用と思う書籍を列挙しようと思います。頻度主義統計学(フツーの統計学)をある程度理解している前提です。小生は頭が良くないのでベイズを理解するのにとても時間がかかりました(今でもちょっと知識があやしい)が、これらの本を組み合わせれば理解が深まることでしょう。
■ベイズを理解する上で有用な和書
")
・この本を久保先生が出版してくれたおかげで初級~入門の知識をさくっと入手できるようになりました。BUGSやRコードも著者サイトからダウンロードできるし言うことなしです。ベイズを勉強しよう!と思ったら必ず入手すべき本です。

・久保先生の本は直観的にベイズを理解できるようになっていますが、理論が手薄です。ベイズ理論の入門はこの本が優れています。頻度主義統計学からベイズ統計学の理論的な架け橋になっています。数式と図のバランスが絶妙です。ただし、この本にはMCMCの記述がないので別の本で勉強する必要ががあるでしょう。
")
・MCMCについては伊庭先生のこの本が決定的に分かりやすいと思います。上記の久保先生の本と合わせれば基礎は十分でしょう。
")
・過去何回か紹介しましたが、この本は名著だと思います。Rコードが豊富です。しかもほとんどパッケージが使われておらず、アルゴリズムがRコードで実装されていますので、コードを解読するとアルゴリズムが理解できます。どちらかというと時系列解析をベイズでやりたい人向けですが、MCMCのサンプルコードも登場するので、階層ベイズに興味がある人にとっても有用と思います。

・石田先生のMCMC本。Rのサンプルコードが豊富な極め付けのような本です。モンテカルロ積分の基礎から収束判定の数式がしっかり書いてあるなどかゆいところに手が届く感じですね。中級~上級者はこの本で勉強するとよいと思います。私もこれからこの本にトライします。
■最後に
日本のベイズ本はWinBUGSでのMCMCを紹介する本が多いのですが、残念ながらWinBUGSは開発がストップしちゃっています。JAGSやSTANなどの代替ツールが登場してきているので、今後はこのようなものが主流になってくるのだと思います。ちなみに、和書ではこれらのツールを詳述するものはありません。体系的な書籍の登場が待たれるところです。
日本でもベイズ統計学に関する本が増えてきました。RやWinBUGSの普及ともにベイズが身近な存在になってきています。しかし、入門書などでは「主観確率」を扱えてビジネスに有用とか書いてありますが、なかなか一般企業でビジネスに使われている状況にはなっていないのではないかと思っています。
その理由はベイズモデルの複雑さ(柔軟さ)にあるのではないかと思います。たとえば、普通のロジットモデルに慣れてしまうと、階層ベイズを使ったロジットモデルを理解するのにちょっとしたハードルがあるように感じられます(少なくとも私はそうでした)。WinBUGSというMCMCサンプラーでモデリングするんだ~というところはなんとなく分かるんですが、モデル式をどのように記述すればいいのかイマイチ想像がつかないのです。
これから紹介する本のようにこのあたりの学習のしづらさを補うものが登場してきましたが、まだまだ入門~中級あたりをサポートする書籍が少ないのが現状のようです。様々なBUGSモデルとRコードを併記したベイズモデルの事例集があると便利と思うのですが、どこかの出版社で企画してくれないかな・・・。
そんなんなこんなで、以下、ベイズ上達のために有用と思う書籍を列挙しようと思います。頻度主義統計学(フツーの統計学)をある程度理解している前提です。小生は頭が良くないのでベイズを理解するのにとても時間がかかりました(今でもちょっと知識があやしい)が、これらの本を組み合わせれば理解が深まることでしょう。
■ベイズを理解する上で有用な和書
データ解析のための統計モデリング入門――一般化線形モデル・階層ベイズモデル・MCMC (確率と情報の科学)
- 作者: 久保 拓弥
- 出版社/メーカー: 岩波書店
- 発売日: 2012/05/19
- メディア: 単行本
・この本を久保先生が出版してくれたおかげで初級~入門の知識をさくっと入手できるようになりました。BUGSやRコードも著者サイトからダウンロードできるし言うことなしです。ベイズを勉強しよう!と思ったら必ず入手すべき本です。
- 作者: 渡部 洋
- 出版社/メーカー: 福村出版
- 発売日: 1999/09
- メディア: 単行本
・久保先生の本は直観的にベイズを理解できるようになっていますが、理論が手薄です。ベイズ理論の入門はこの本が優れています。頻度主義統計学からベイズ統計学の理論的な架け橋になっています。数式と図のバランスが絶妙です。ただし、この本にはMCMCの記述がないので別の本で勉強する必要ががあるでしょう。
計算統計 2 マルコフ連鎖モンテカルロ法とその周辺 (統計科学のフロンティア 12)
- 作者: 伊庭 幸人
- 出版社/メーカー: 岩波書店
- 発売日: 2005/10/27
- メディア: 単行本
・MCMCについては伊庭先生のこの本が決定的に分かりやすいと思います。上記の久保先生の本と合わせれば基礎は十分でしょう。
- 作者: 姜 興起
- 出版社/メーカー: 共立出版
- 発売日: 2010/07/24
- メディア: 単行本
・過去何回か紹介しましたが、この本は名著だと思います。Rコードが豊富です。しかもほとんどパッケージが使われておらず、アルゴリズムがRコードで実装されていますので、コードを解読するとアルゴリズムが理解できます。どちらかというと時系列解析をベイズでやりたい人向けですが、MCMCのサンプルコードも登場するので、階層ベイズに興味がある人にとっても有用と思います。
- 作者: C.P.ロバート
- 出版社/メーカー: 丸善出版
- 発売日: 2012/08/23
- メディア: ムック
・石田先生のMCMC本。Rのサンプルコードが豊富な極め付けのような本です。モンテカルロ積分の基礎から収束判定の数式がしっかり書いてあるなどかゆいところに手が届く感じですね。中級~上級者はこの本で勉強するとよいと思います。私もこれからこの本にトライします。
■最後に
日本のベイズ本はWinBUGSでのMCMCを紹介する本が多いのですが、残念ながらWinBUGSは開発がストップしちゃっています。JAGSやSTANなどの代替ツールが登場してきているので、今後はこのようなものが主流になってくるのだと思います。ちなみに、和書ではこれらのツールを詳述するものはありません。体系的な書籍の登場が待たれるところです。
PythonでMCMC(メトロポリス法)-ベイズ統計学 [統計学]
最近は状態空間モデリングの勉強をしています。その一環できちんとMCMCを理解しようとあれこれ資料を漁っていました。マルコフ連鎖モンテカルロ法を実装してみようというブログ記事や「計算統計 2 マルコフ連鎖モンテカルロ法とその周辺 」などを読みつつ、メトロポリス法というシンプルなMCMCをPythonで実装してみました。
」などを読みつつ、メトロポリス法というシンプルなMCMCをPythonで実装してみました。
■計算条件
・2変量正規分布からサンプリング
【2変量正規分布】
=\frac{1}{Z}exp(-\frac{x_1^2-2bx_1x_2+x_2^2}{2}))

・b = 0.5 (ここでは適当にこの値にした)
・burn-in = 0
-サンプリングの挙動を確認するためバーンインは0とした
■Pythonコード
■結果
・2変量の動き
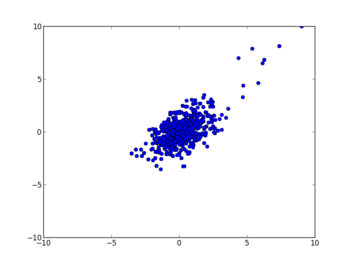
#初期値から数サンプルはふらふらと彷徨うが、しばらくすると最大値付近に収束
・p(x1,x2)の収束状況
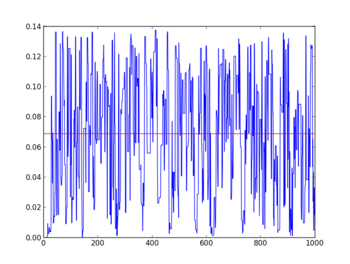
#時系列にグラフ化すると収束性を確認することができる
■感想
・メトロポリス法はとシンプルなアルゴリズムで理解しやすい
・この調子でメトロポリスヘイスティング法とギブスサンプラー法も理解する予定
・GAなんかを併用する手法はないのかな?
■参考文献
・伊庭先生の解説が一番分かりやすいと思う。これが少し難易度が高いなら久保先生のベイズ本 などを最初に読むといいです
などを最初に読むといいです
・あんまり注目されていないような気がするんだけど、この本も名著です。MCMCのRコードもあります。状態空間モデルのRコードはとても重宝しています。北川先生の時系列本 と合わせて読むと理解がより深まりますね!
と合わせて読むと理解がより深まりますね!
■計算条件
・2変量正規分布からサンプリング
【2変量正規分布】
・b = 0.5 (ここでは適当にこの値にした)
・burn-in = 0
-サンプリングの挙動を確認するためバーンインは0とした
■Pythonコード
#!/usr/bin/env python
#-*- coding:utf-8 -*-
import math
import random
import numpy as np
import matplotlib.pyplot as plt
def metropolis(func, start=10.0, delta=2.0, burn_in=0, seed=1):
metro_iter = _metropolis(func, start, delta, seed)
for i, value in enumerate(metro_iter):
if i > burn_in:
yield value
break
for value in metro_iter:
yield value
def _metropolis(func, start, delta, seed):
random.seed(seed)
initial_x1 = start
initial_x2 = start
initial_fx = func(initial_x1, initial_x2)
proposed_x1, proposed_x2, proposed_fx = 0.0, 0.0, 0.0
for j in range(1,1000):
proposed_x1 = initial_x1 + random.uniform(-delta, delta)
proposed_x2 = initial_x2 + random.uniform(-delta, delta)
proposed_fx = func(proposed_x1, proposed_x2)
ratio = proposed_fx / initial_fx
if ratio > 1.0 or ratio > random.random():
initial_x1, initial_x2, initial_fx = proposed_x1, proposed_x2, proposed_fx
yield proposed_x1, proposed_x2, proposed_fx
else:
yield initial_x1, initial_x2, initial_fx
def main():
b = 0.5
Z = 2*math.pi/math.sqrt(1.0-b**2.0)
f = lambda x1, x2: math.exp(-(x1**2-2*b*x1*x2+x2**2)/2)/Z
xb1 = []
xb2 = []
fxb1 = []
for x1, x2, fx in metropolis(f):
xb1.append(x1)
xb2.append(x2)
fxb1.append(fx)
tx = range(1,len(fxb1)+1)
md = [np.median(fxb1)]*(len(fxb1))
plt.plot(xb1,xb2,"bo")
plt.axis([-10, 10, -10, 10])
plt.show()
plt.plot(tx, fxb1)
plt.plot(tx, md, "r")
plt.axis([0, 1000, 0, 0.14])
plt.show()
if __name__ == '__main__':
main()
■結果
・2変量の動き
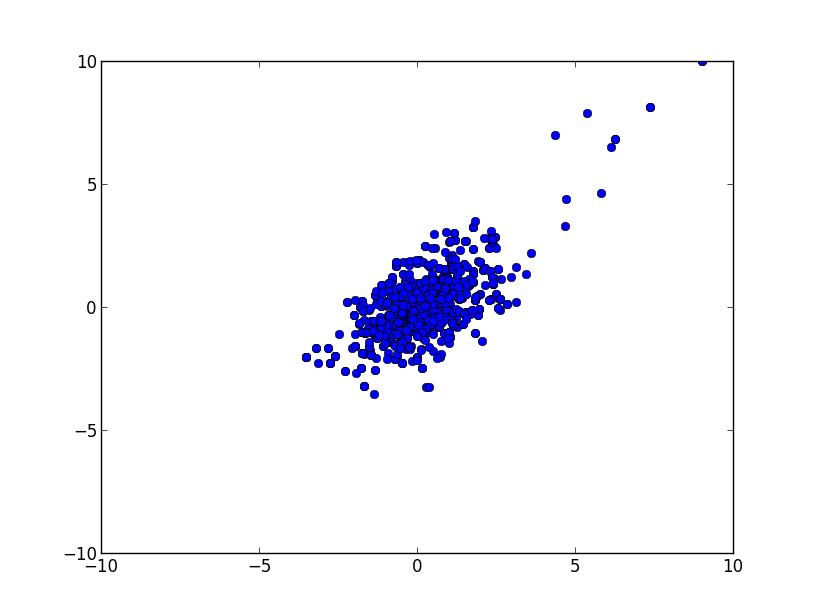
#初期値から数サンプルはふらふらと彷徨うが、しばらくすると最大値付近に収束
・p(x1,x2)の収束状況
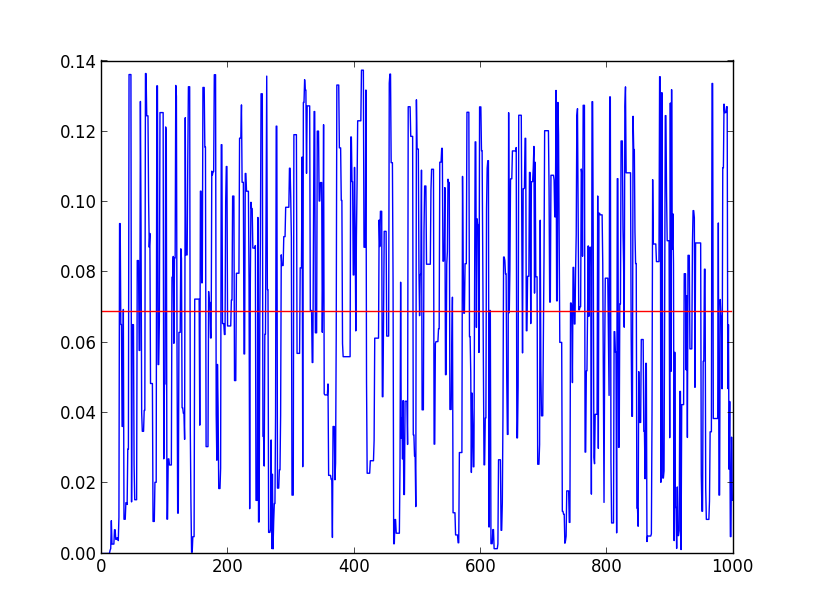
#時系列にグラフ化すると収束性を確認することができる
■感想
・メトロポリス法はとシンプルなアルゴリズムで理解しやすい
・この調子でメトロポリスヘイスティング法とギブスサンプラー法も理解する予定
・GAなんかを併用する手法はないのかな?
■参考文献
計算統計 2 マルコフ連鎖モンテカルロ法とその周辺 (統計科学のフロンティア 12)
- 作者: 伊庭 幸人
- 出版社/メーカー: 岩波書店
- 発売日: 2005/10/27
- メディア: 単行本
・伊庭先生の解説が一番分かりやすいと思う。これが少し難易度が高いなら久保先生のベイズ本
- 作者: 姜 興起
- 出版社/メーカー: 共立出版
- 発売日: 2010/07/24
- メディア: 単行本
・あんまり注目されていないような気がするんだけど、この本も名著です。MCMCのRコードもあります。状態空間モデルのRコードはとても重宝しています。北川先生の時系列本
データ解析のための統計モデリング入門 [統計学]
データ解析のための統計モデリング入門――一般化線形モデル・階層ベイズモデル・MCMC (確率と情報の科学)
- 作者: 久保 拓弥
- 出版社/メーカー: 岩波書店
- 発売日: 2012/05/19
- メディア: 単行本
北大の久保先生のベイズ本を読みました。感想を書きます。
結論から言うと、これは良書です。図が豊富かつ分かりやすい文体なので初学者でもベイズのイメージを頭に浸透させることができるでしょう。そして、GLM(一般化線形モデル)から順を追って解説されているため、伝統的(頻度主義)な統計学にしか知らなくてもベイズの考え方に無理なく馴染むことができます。
久保先生が生態学のご専門なので、サンプルデータは植物の種子数など生態学系のものになりますが、「まえがき」にあるように専門外の人でも全く問題なく読むことができます。そして、生態学における「個体差」や「場所差」はビジネス的にはマーケティングに通じる考え方です。個体差 = 顧客異質性 ⇒ One to One マーケティング というわけです。
マーケティングを題材としたベイズ本もいくつか出版されていますが、ここまで分かりやすいものは残念ながらマーケティング分野にはないと思います。佐藤先生の「ビッグデータ時代のマーケティング―ベイジアンモデリングの活用 (KS社会科学専門書)
最後に、この本ではWinBugsというMCMCサンプラーが使われていますが、このソフトウェアは開発が停止しているようです。開発が現在でも継続しているものにJAGSやStanなどがあるようですが、これらに関する記載は本書にはありません。JAGSについては解説がある洋書は見つかりましたが、Stanについては今のところGoogle先生だけが頼みのようです。
◆参考文献
■ビッグデータ時代のマーケティング
")
ビッグデータ時代のマーケティング―ベイジアンモデリングの活用 (KS社会科学専門書)
- 作者: 佐藤 忠彦
- 出版社/メーカー: 講談社
- 発売日: 2013/01/22
- メディア: 単行本(ソフトカバー)
・GSSMの佐藤先生の本です。以前の記事でも紹介しましたが、マーケティングのベイズ本として非常に分かりやすいです。階層ベイズから粒子フィルターの適用まで最新のマーケティングサイエンスの技術が紹介されています。
■Doing Bayesian Data Analysis: A Tutorial Introduction with R

Doing Bayesian Data Analysis: A Tutorial Introduction with R
- 作者: John Kruschke
- 出版社/メーカー: Academic Press
- 発売日: 2010/11/10
- メディア: ハードカバー
・久保先生の本には記述がないJAGSについてはこちらの本がよさそうです。まだ持っていないのでなんとも言えませんが、Amazon.comの評価がものすごく良いのでとても気になっています。
バランスサンプリング(Cube法) [統計学]
効果的なサンプリング(標本抽出)について調べていたところ、バランスサンプリング(Cube法)という方法が良いらしいので早速試してみた。iAnalysisさんのブログ「調査のためのサンプリング」を参考にした。
■実験条件
1.データ
・MU284(アイスランドのデータ(税収、党の議席数など)-284件
2.R Package
sampling package
3.比較
①Balanced SamplingとRandom Samplingについて変数:RMT85のHorvitz-Thompson推定量と全体合計との比較
②Balanced SamplingとRandom Samplingについてboxplotで比較
4.結果
①Horvitz-Thompson推定量と全体合計との比較
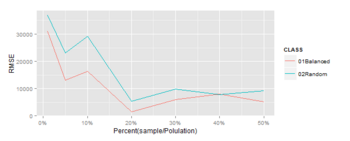
※Horvitz-Thompson推定量と全体合計のRMSEをプロット(この方法で検証あってるかちょっと不安)
②boxplotで比較
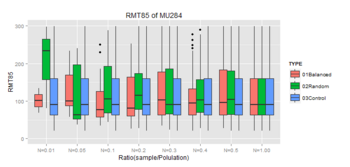
※Controlは母集団のBoxplot
★このデータの場合、バランスサンプリングは10%程度のサンプルで母集団との類似性が大きくなってきている。効果ありそう。もうちょっと調べてみようと思う。
6.コード
■参考文献
・概説 標本調査法 (統計ライブラリー)
")
cube法について書かれている和書はなさそうですが、標本調査の基礎にいてはこの本がわりと分かりやすいです。
・Sampling Algorithms (Springer Series in Statistics)
")
cube法について詳しく書いてあるのはこの本みたいです。本当にちゃんとやろうとすると洋書になっちゃうんですよね。やっぱり学者の層が薄いのでしょうか。いずれ読まなきゃなこの本。
■実験条件
1.データ
・MU284(アイスランドのデータ(税収、党の議席数など)-284件
2.R Package
sampling package
3.比較
①Balanced SamplingとRandom Samplingについて変数:RMT85のHorvitz-Thompson推定量と全体合計との比較
②Balanced SamplingとRandom Samplingについてboxplotで比較
4.結果
①Horvitz-Thompson推定量と全体合計との比較
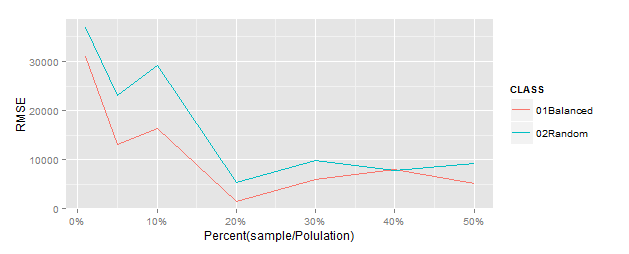
※Horvitz-Thompson推定量と全体合計のRMSEをプロット(この方法で検証あってるかちょっと不安)
②boxplotで比較
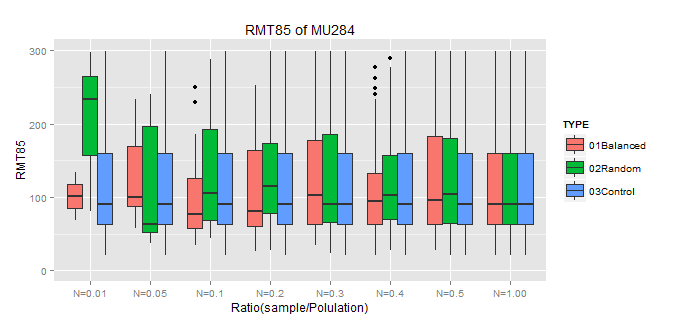
※Controlは母集団のBoxplot
★このデータの場合、バランスサンプリングは10%程度のサンプルで母集団との類似性が大きくなってきている。効果ありそう。もうちょっと調べてみようと思う。
6.コード
####ライブラリ
library(sampling)
library(ggplot2)
library(scales)
data(MU284) #アイスランドのデータ(税収、党の議席数など)
#####サンプリング
###ランダムサンプリング関数
rsmpl <- function(DATA, i) {
#i: 0 < i < 1
nsample <- round(nrow(DATA)*i)
p <<- rep(nsample/nrow(DATA), nrow(DATA))
s <<- srswor(nsample, nrow(DATA))
train <<- DATA[s==1, ]
test <<- DATA[s==0, ]
}
####バランスサンプリング関数
csmpl <- function(X, DATA, i) {
#i: 0 < i < 1
nsample <- round(nrow(DATA)*i)
p <<- rep(nsample/nrow(DATA), nrow(DATA))
s <<- samplecube(X, p, 1, FALSE)
train <<- DATA[s==1, ]
test <<- DATA[s==0, ]
}
#csmpl(X, smpl, 0.01)
###サンプルと母集団の統計量比較
stat_comp <- function(sample, comp) {
#出力したい変数に限定していると仮定
rbind(summary(sample)[4, ], summary(comp)[4, ])
}
#stat_comp(train, smpl)
###Horvitz-Thompson 推定量
HT_comp <- function(sample, comp, pik, s) {
HT <- HTestimator(sample, pik[s==1])
CP <- sum(comp)
RMSE <- sqrt((HT-CP)^2)
R <<- data.frame(HT=HT, COMP=CP, RMSE=RMSE)
}
#HT_comp(train$age, smpl$age, p ,s)
####main()
###Test of Random Sampling
n <- c(0.01, 0.05, 0.1, 0.2, 0.3, 0.4, 0.5)
RSLT1 <- data.frame(HT=NULL, COMP=NULL, RMSE=NULL)
for(i in 1:length(n)) {
rsmpl(MU284, n[i])
HT_comp(train$RMT85, MU284$RMT85, p, s)
RSLT1 <- rbind(RSLT1, R)
}
TMP <- data.frame(Smpl=rep(281,7)*n, Pop=rep(281,7), PCNT=n)
RSLT1 <- cbind(TMP, RSLT1)
###Test of Balanced Sampling
n <- c(0.01, 0.05, 0.1, 0.2, 0.3, 0.4, 0.5)
RSLT2 <- data.frame(HT=NULL, COMP=NULL, RMSE=NULL)
X <-cbind(MU284$P75,MU284$CS82,MU284$SS82,MU284$S82,MU284$ME84,MU284$REV84)
for(i in 1:length(n)) {
csmpl(X, MU284, n[i])
HT_comp(train$RMT85, MU284$RMT85, p, s)
RSLT2 <- rbind(RSLT2, R)
}
TMP <- data.frame(Smpl=rep(281,7)*n, Pop=rep(281,7), PCNT=n)
RSLT2 <- cbind(TMP, RSLT2)
####可視化
RSLT1$CLASS <- "02Random"
RSLT2$CLASS <- "01Balanced"
RSLT <- rbind(RSLT1, RSLT2)
RSLT$CLASS <- as.factor(RSLT$CLASS)
gg <- ggplot(RSLT, aes(x=PCNT, y=RMSE, colour=CLASS)) + geom_line()
gg <- gg + xlab("Percent(sample/Polulation)") +
scale_x_continuous(labels = percent)
gg
####Box-plotで分布を比較
###Test of Random Sampling
n <- c(0.01, 0.05, 0.1, 0.2, 0.3, 0.4, 0.5)
RAND <- NULL
for(i in 1:length(n)) {
rsmpl(MU284, n[i])
tmp <- data.frame(n=rep(n[i], nrow(train)),
RMT85=train$RMT85,
class=rep(paste0("N=",n[i]), nrow(train)))
RAND <- rbind(RAND, tmp)
}
tmp <- data.frame(n=rep(1.00, nrow(MU284)),
RMT85=MU284$RMT85,
class=rep("N=1.00", nrow(MU284)))
RAND <- rbind(RAND, tmp)
###Test of Balanced Sampling
n <- c(0.01, 0.05, 0.1, 0.2, 0.3, 0.4, 0.5)
BLNC <- NULL
X <-cbind(MU284$P75,MU284$CS82,MU284$SS82,MU284$S82,MU284$ME84,MU284$REV84)
for(i in 1:length(n)) {
csmpl(X, MU284, n[i])
tmp <- data.frame(n=rep(n[i], nrow(train)),
RMT85=train$RMT85,
class=rep(paste0("N=",n[i]), nrow(train)))
BLNC <- rbind(BLNC, tmp)
}
tmp <- data.frame(n=rep(1.00, nrow(MU284)),
RMT85=MU284$RMT85,
class=rep("N=1.00", nrow(MU284)))
BLNC <- rbind(BLNC, tmp)
###Control
n <- c(0.01, 0.05, 0.1, 0.2, 0.3, 0.4, 0.5)
CNTR <- NULL
for(i in 1:length(n)) {
tmp <- data.frame(n=rep(n[i], nrow(MU284)),
RMT85=MU284$RMT85,
class=rep(paste0("N=",n[i]), nrow(MU284)))
CNTR <- rbind(CNTR, tmp)
}
tmp <- data.frame(n=rep(1.00, nrow(MU284)),
RMT85=MU284$RMT85,
class=rep("N=1.00", nrow(MU284)))
CNTR <- rbind(CNTR, tmp)
####可視化
###データ加工
RAND$TYPE <- "02Random"
BLNC$TYPE <- "01Balanced"
CNTR$TYPE <- "03Control"
BOXP <- rbind(RAND, BLNC)
BOXP <- rbind(BOXP, CNTR)
BOXP$class <- as.factor(BOXP$class)
BOXP$TYPE <- as.factor(BOXP$TYPE)
gg <- ggplot(BOXP, aes(class, RMT85)) +
geom_boxplot(aes(fill = TYPE)) +
ylim(0, 300) + ggtitle("RMT85 of MU284") +
xlab("Ratio(sample/Polulation)")
gg
■参考文献
・概説 標本調査法 (統計ライブラリー)
- 作者: 土屋 隆裕
- 出版社/メーカー: 朝倉書店
- 発売日: 2009/08
- メディア: 単行本
cube法について書かれている和書はなさそうですが、標本調査の基礎にいてはこの本がわりと分かりやすいです。
・Sampling Algorithms (Springer Series in Statistics)
Sampling Algorithms (Springer Series in Statistics)
- 作者: Yves Tillé
- 出版社/メーカー: Springer
- 発売日: 2010/11/19
- メディア: ペーパーバック
cube法について詳しく書いてあるのはこの本みたいです。本当にちゃんとやろうとすると洋書になっちゃうんですよね。やっぱり学者の層が薄いのでしょうか。いずれ読まなきゃなこの本。
MCMC [統計学]
")
- 作者: 姜 興起
- 出版社/メーカー: 共立出版
- 発売日: 2010/07/24
- メディア: 単行本
また新たなベイズ本が出版された。ここ数か月はベイズ本が出版ラッシュにあって飛ぶ鳥を落とす勢いである。無料のRの普及とともにベイズも一般化していくのだろう。
ところで、↑に挙げた本はRのソースコードが丁寧に書かれていることが特徴のようだ。Rのパッケージをインストールしてどうこうという話ではなく、関数のプログラミングが一から説明されていて、コードを読むことによってベイズの中身がどうなっているのか理解可能になっている。これは、少なくとも日本語の類書には例を見なかったのではないだろうか。
小生は普段SASを使っている。SAS9.2ではmcmcプロシージャなるものが標準で搭載されているので↓のサイトでもみて遊んでみようかなと思っている。そろそろ本格的にベイズを実務に導入すべき時に来ている気がする。
http://d.hatena.ne.jp/triadsou/20091204/1259922014
ベイズ統計データ分析 [統計学]
")
ベイズ統計データ分析―R & WinBUGS (統計ライブラリー)
- 作者: 古谷 知之
- 出版社/メーカー: 朝倉書店
- 発売日: 2008/09
- メディア: 単行本
ベイズ本を初めて買った。ここ2年程度でベイズ関連の和書が増えている。これまではベイズを勉強しようとすると洋書しかなかったらしい(今でもベイズどころか統計を本当に勉強しようとしたら洋書は避けられないわけだが)。洋書は敷居が高し、近々、統数研のTH先生の講義でも使うので買ってみた。
ベイズと言えば、「ナイーブベイズ」によるスパムフィルターとか「ベイジアンネット」を使って消費者行動モデルを構築するとかとにかくいろんなことに使われているらしいし、米国のビジネススクールでも必修科目になっているとか。という事前知識はあるわけだが、なぜそこまで注目されているのかイマイチわかっていないワタクシ・・・(小生が通っていたGSSM(筑波大学院経営システム科学専攻)でも関連講義なかったし)。主観確率を使って合理的な意思決定をするとか言われてもピンときません。とにかく勉強してみることにするぞと。
ところで、↑の本はベイズによる実データの解析に関するほとんど唯一とも言える和書だ。だが、Amazonでの評価が著しく悪く、☆1.5個分の評価しかない。理由はこの本のウリであるRとWINBUGSのコードが出鱈目だということらしい。小生が入手したのは2刷だが、改善されているのだろうか。まあ、Rについての知識は多少はあるので何とか対処する努力はしてみる。読み終えたらレポートしようと思う。